Managing SRM
How Statsig detects and surfaces sample ratio mismatch (SRM) in experiments and how to debug skewed traffic splits before trusting results.
What is SRM
SRM, or sample ratio mismatch, is a problem with experiments characterized by too many units in some groups and too few in others.
The example below is an exposure crosstab of an experiment with SRM. The group percentages may look similar. However, if an assignment system splits traffic evenly, an imbalance this extreme or greater has less than a 0.01% chance of occurring randomly.
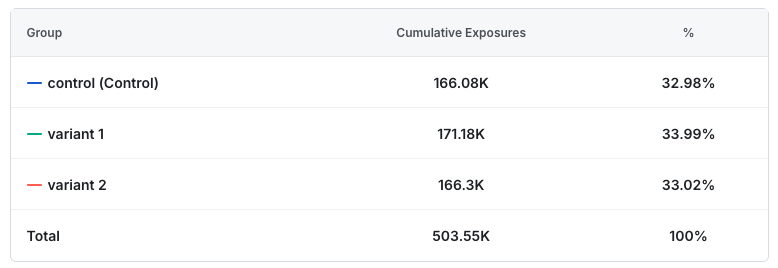
Statsig and most experiment platforms normalize metrics per-user: they measure a count metric as total count divided by unique users in the experiment. In isolation, having more users in one group isn't a problem. However, SRM is problematic for the following reason.
Why SRM is an issue
SRM is an issue because it's usually non-random: the extra or missing traffic is not identical to the original traffic. Common causes of SRM include:
- A bug causes a user's client or browser to crash before it can send an exposure log. Statsig doesn't re-expose users who don't return, but includes users who return. This introduces bias in measurement.
- A conditional dependency filters which users Statsig exposes based on some characteristic for one or more groups, making those groups non-identical to other groups and biasing measurement.
- A script bulk-exposes users one group at a time, and the system truncates logs after a certain count, which cuts off the last group's exposures.
SRM checks are critical because they detect these effects even at low rates. Even low-rate SRM can lead to serious inaccuracy in experiment readouts.
How SRM is detected
Statsig detects SRM using a chi-squared test, which analyzes categorical data to determine whether observed frequencies match expected frequencies. For example, in the experiment above, the expected distribution is 167.85k units per group, but the observed distribution is [166.08k, 171.18k, 166.30k].If the p-value of the test is low, the null hypothesis that the groups are identical is rejected, and the result indicates a difference between the groups' observed and expected assignment rates.
What to do if an experiment has SRM
On Statsig, SRM creates a warning or failure state on an experiment's health check when Statsig detects it, depending on how extreme the SRM is.
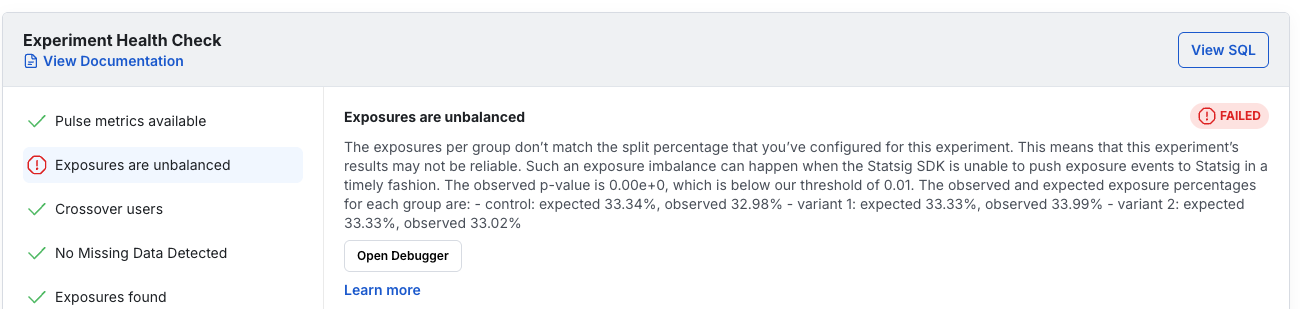
This often causes concern: teams don't want to reset their experiment and lose collected data, and if there is an underlying issue it may reproduce after a reset.
Follow these steps to diagnose and address SRM:
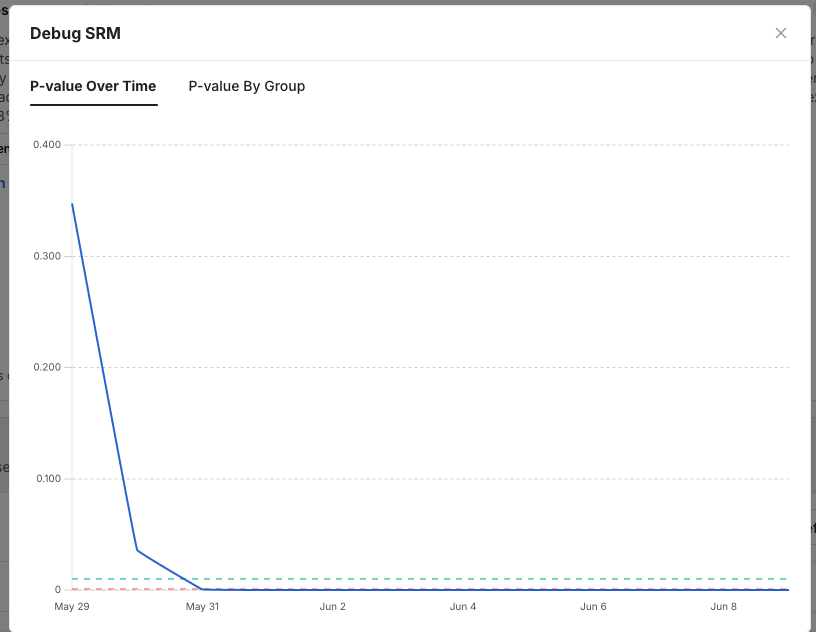
1.) Check the time series data
Statsig generates a chart of SRM p-value over time. If the chart is noisy and fluctuates, the alert is more likely a false positive. If the p-value consistently trends down to 0, there is likely a real assignment issue.
The following is an example of a p-value chart that indicates a real issue.
2.) Understand if there's a clear root cause for SRM
Use Statsig's SRM debugger or analyze exported exposures to determine whether a specific segment is driving SRM. Often a bug affects only one platform such as Android, or only users with low internet speeds. If you find and fix the bug, you can restart the experiment safely.
If the issue is clearly isolated, filtering out that segment from analysis is also reasonable when the experiment was expensive or required a long data collection period.
At this point, you should have a reasonable sense of whether there is a real issue. Use that assessment to decide next steps.
3.) Assess options
In many cases, the best path is to investigate, fix, and restart. In some cases, the SRM may be mild enough, and the experiment low-risk enough, that making a decision with the affected data is acceptable.
Statsig strongly recommends against proceeding without investigation and considers restarting the experiment a best practice, ideally after investigating any potential SRM cause.
Was this helpful?