Online Evals
Run online AI evaluations in Statsig to grade model outputs in production on real traffic, including shadow runs for candidate prompts and models.
This feature is in Early Access. During this time, aspects of the functionality may still be developed, and this documentation may not always be up to date. If you have any questions, contact Statsig Support.
What are online evals
Online evals grade model output in production on real-world use cases. You can run the "live" version of a prompt and also shadow-run "candidate" versions without exposing users to them. Grading works directly on the model output and doesn't require a ground truth to compare against. Use online evals when you want to grade output on live production traffic without a ground truth to compare against. Use offline evals instead when you can grade against a fixed test set with ideal answers before release.
Steps to run online evals in Statsig:
- Create a Prompt that contains the instruction for your task (for example, "Summarize ticket content. Do not include email addresses or credit card numbers in the summary"). Create a v2 prompt that improves on this.
- In your app, produce model output using the v1 and v2 prompts. Your app renders the output from v1 to the user, and an LLM-as-a-judge judges the outputs from both v1 and v2.
- Statsig logs the grades from v1 and v2 for comparison.
Statsig isn't accepting new customers for AI Evals.
Create/analyze an online eval in 15 minutes
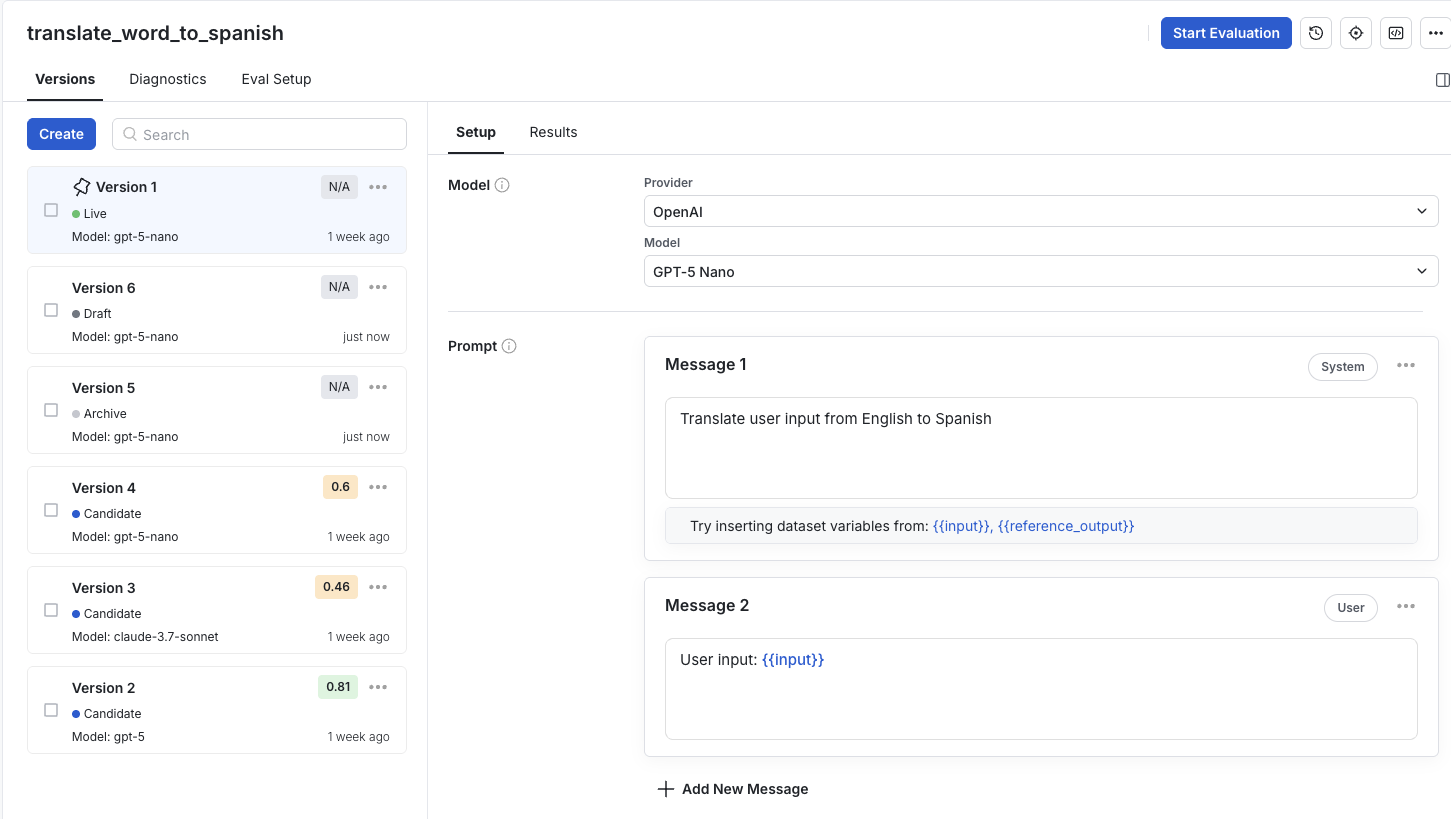
1. Identify the prompts you want to serve
In Prompts, there are four prompt types: Live, Candidate, Draft and Archive. Before starting an online evaluation, organize your prompt versions into these categories:
Live prompt is the version actively served to users.
Candidate prompts don’t appear to users, but Statsig still serves them to your code. Statsig processes the user’s input against them and logs and grades their outputs alongside the live version.
Draft prompts are the offline prompts you iterate on in the console, before deciding that you want to serve them. To start serving them, promote them to "Candidate" or "Live."
Archive prompts are inactive versions that you don't iterate on, kept offline.
Prompts that you can access in code comprise the Live version and Candidate versions.
2. Load your prompts in code and run completions on user input
The example below shows how to integrate prompts in your application using the Statsig AI SDKs. After you retrieve your Live or Candidate prompts, pass in the appropriate values to replace the macros in your prompt (replace{{input}} with the user input). Then run completions on each of these prompts.const prompts = statsigAI.getPrompt(user, "ai_config_name");
// get the live prompt
const livePrompt = prompts.getLive();
// get the candidate prompts
const candidatePrompts = prompts.getCandidates();
// get the live prompt messages
const livePromptMessages = livePrompt.getPromptMessages({ input: userInput });
// run completions on your live prompt and show the output to the user
const liveOutput = client.completions.create(
my_model,
livePromptMessages,
(temperature = livePrompt.getTemperature())
);
// simulateneously run completions on the candidate prompts to get their output
3. Score your output using graders
After you have a completion’s output, evaluate it using a grader: either one created in Statsig or a custom grader of your choice. The resulting score must always fall within the range of 0 to 1.
4. Log eval results to Statsig
Log your scores as events in Statsig to view the results in your console.
// Log the results of the eval
statsigAI.logEvalGrade(user, livePromptVersion, 0.5, "my_grader", {
session_id: "1234567890",
});
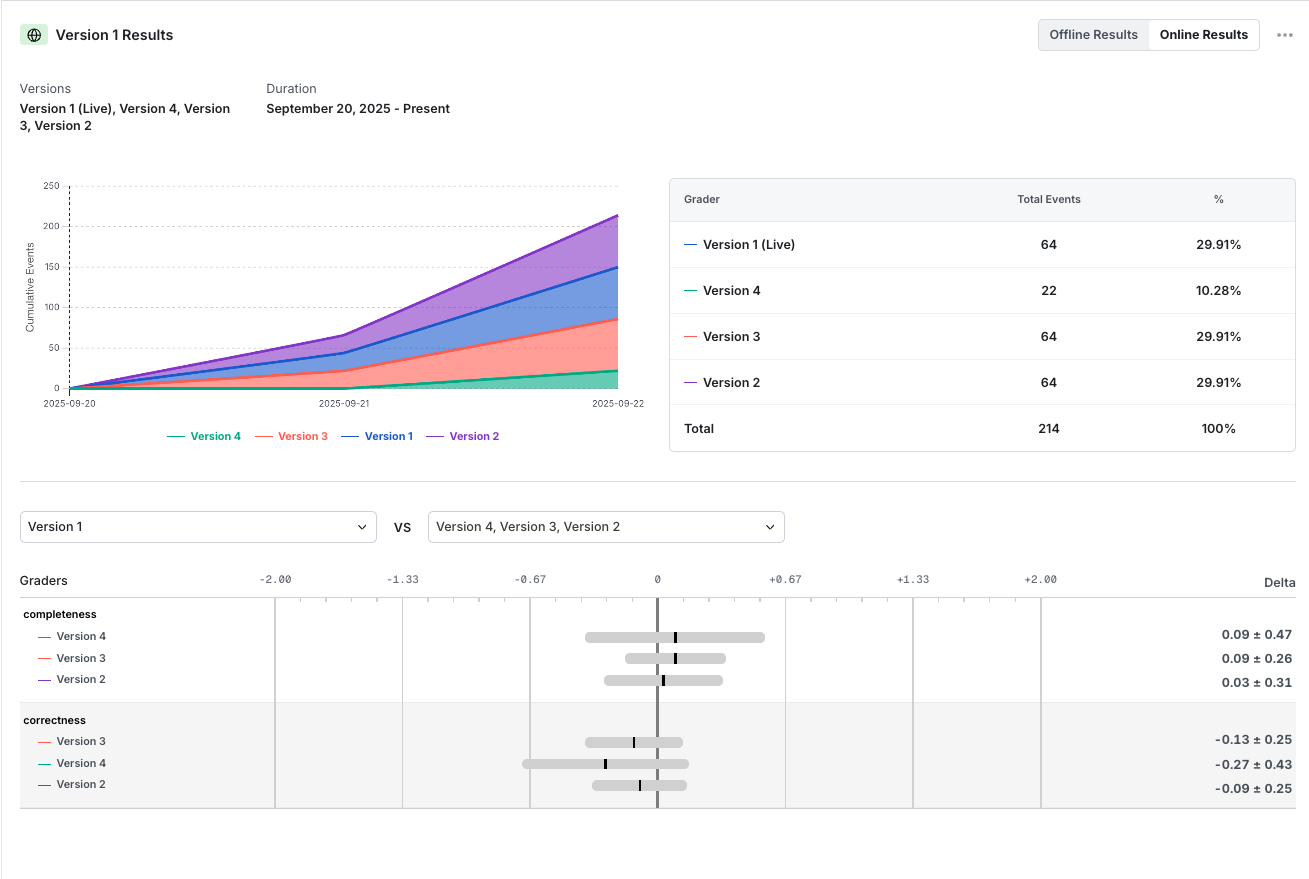
5. View results in Statsig
View these results in Statsig. Select the version you want to evaluate and the versions to compare it against. This end-to-end online eval helps you iterate on your prompts and gain insights.
Was this helpful?