SDKs and APIs
How does bucketing in the Statsig SDKs work?
See How Evaluation Works.Can I add a layer to a running experiment?
No. Layers are fixed once an experiment starts to preserve the integrity of results. We may support editing layers in the future.Can I rename an existing experiment or feature gate?
Yes, you can rename existing experiments and feature gates after they are created. Note that when you are renaming an entity (e.g., feature gate, experiment, layer), you are only renaming its display name. The underlying ID of the entity (which are referenced your code) remains unchanged as they are immutable to prevent breaking existing implementations.Why define parameters instead of just reading the experiment group?
Parameters let you iterate quickly without code changes and support richer experiment setups. For example:Why aren’t exposures or custom events showing up?
In short-lived environments (scripts, edge workers), the process may exit before events flush. Callstatsig.flush() before shutdown. Details live in the Node.js server SDK docs.
My SDK language isn’t listed. Can I still use Statsig?
Likely yes. Let us know in the Statsig Slack community and we’ll discuss options.How do I retrieve all exposures for a user?
The Users tab shows historical exposures. For hypothetical assignments (e.g., to bootstrap clients) you can callgetClientInitializeResponse on the server. Pass { hash: 'none' } if you need readable keys:
What happens if I check a config that doesn’t exist?
The SDK returns defaults—false for gates and the supplied fallback for experiments/layers. You’ll see the evaluation reason Unrecognized; learn more in SDK debugging. This applies to deleted, archived, or unseen configs (e.g., filtered by target apps).
Feature Gates
If I change the rollout percentage, do existing users keep their result?
Yes. Increasing the pass percentage (e.g., 10% → 20%) keeps the original 10% and adds new traffic until you reach the new percentage. Decreasing it removes the newest slice first. To reshuffle everyone, you must resalt the gate. (Experiments behave differently—use targeting gates for deterministic control.)Statistics
What statistical tests does Statsig use?
We use a two-sample Z-test for most experiments and Welch’s t-test when sample sizes are small or variances differ.How does Statsig handle low sample sizes?
We fall back to Welch’s t-test and offer CUPED/winsorization to boost power.When should I use one-sided vs. two-sided tests?
Use one-sided when you only care about movement in a single direction; it increases power but hides movement in the opposite direction.Experimentation
How do I get started with an A/B test?
If the feature isn’t live yet, wrap it in a feature gate and roll out. If it’s already in production, create an experiment. Results appear in the Pulse view.Can I target experiments to specific users (e.g., iOS only)?
Yes. Use a feature gate with targeting rules as a pre-filter for your experiment.
Billing
What counts as a billable event?
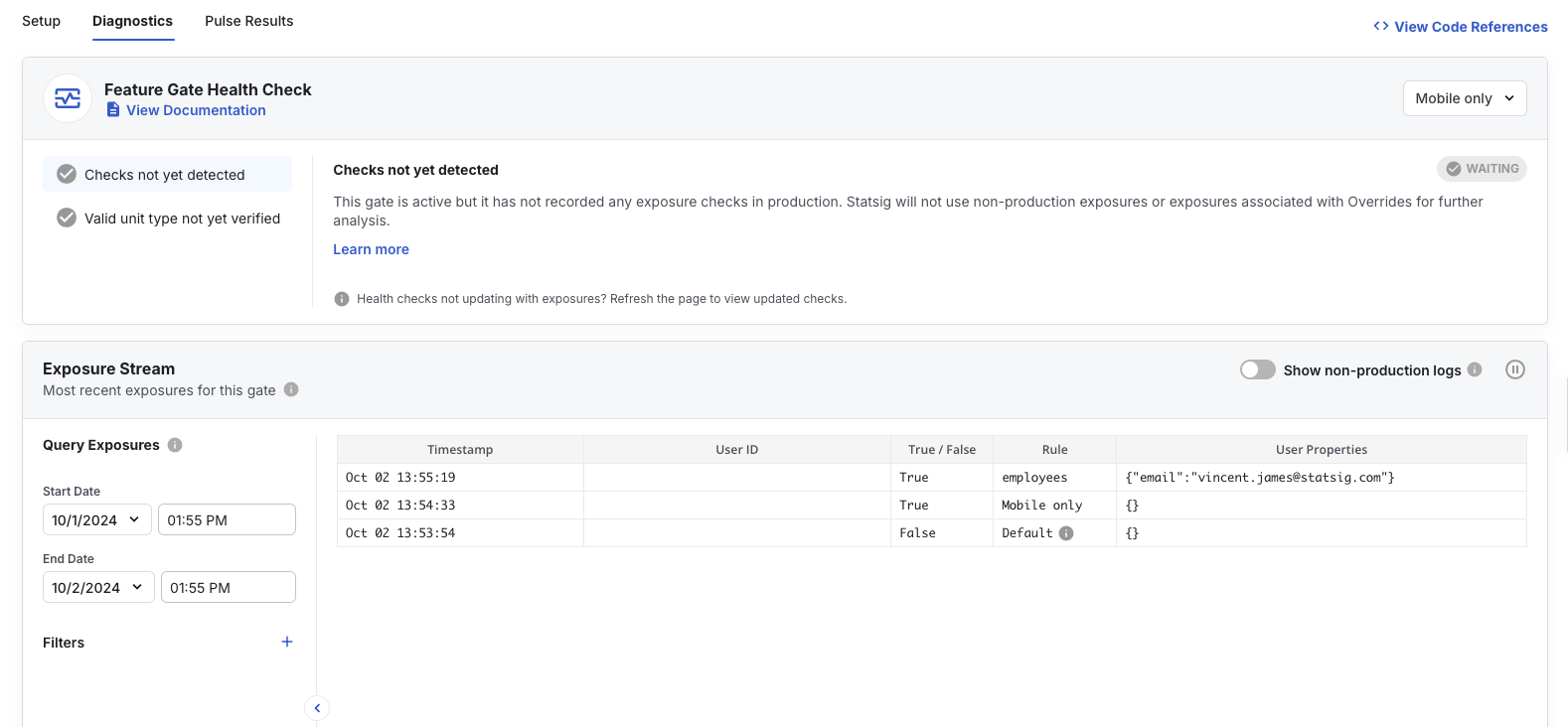
Any gate/experiment check or event logged via the SDK or APIs. Pre-computed metrics and custom metrics based on existing data also count.How do I monitor and manage billable volume?
- Export usage from the Usage and Billing tab.
- Pivot by event to identify heavy hitters.
- Admins receive alerts at 50/75/100% of contract.
How many projects can I create with a Pro subscription?
Each Statsig Pro plan unlocks one project with pro features and 5M events. Additional projects require their own upgrade. Enterprise plans can cover multiple projects—contact us to discuss.Platform Usability
When should I create a new project?
Projects have distinct boundaries. If you’re using the same userIDs and metrics across surfaces, apps or environments, put them in the same project. Create a new project when you’re managing a separate product with unique user IDs and metrics. For example, if you have a marketing website (anonymous users) and a product (signed-in users), you may want to separate them. However, if you want to track success across both you should manage them in the same project. (e.g. from user signup on the marketing website to user engagement within the product) Some reasons to NOT create a new project- to segregate by environment. Statsig has rich support for environments - you can even customize these. You can turn features or experiments on and off by environment.
- to segregate by platform. If you have an iOS app and Web app - it’s helpful to have both collect data in the same project and capture metadata on platform. This lets you look at data by platform, but also understand if you’ve increased the overall metric - or just cannibalized users (pushed the same users from platform to the other platform).