How to Read Experiment Results (Formerly "Pulse")
Read and interpret Statsig experiment results, including scorecards, primary metrics, lift, confidence intervals, and statistical significance indicators.
Read Experiment Results
To read the results of your experiment, go to the Results tab. There you'll find your experiment hypothesis, exposures, and Scorecard.
Exposures
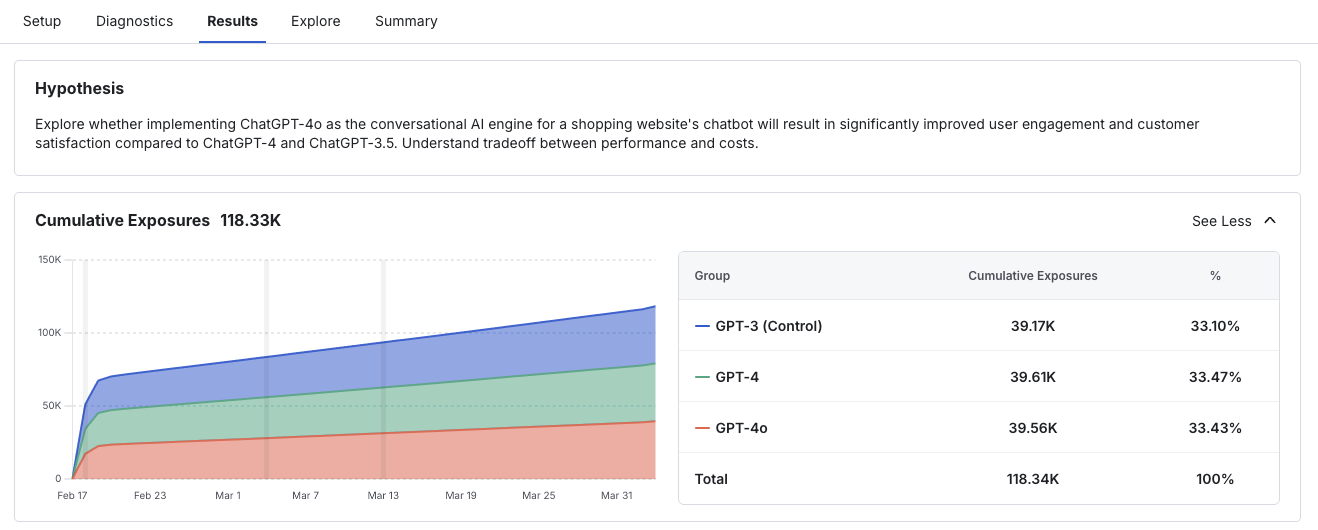
At the top of the Results page is the Exposures Chart. Exposures are the unique experimental units enrolled in the experiment: typically unique users, or devices for device-level experimentation. The timeline shows when the experiment started and how many exposures were enrolled each day. Use this chart to verify the rate at which users entered each group, the total number exposed, and whether the target ratio matches what you configured in experiment setup.
Scorecard
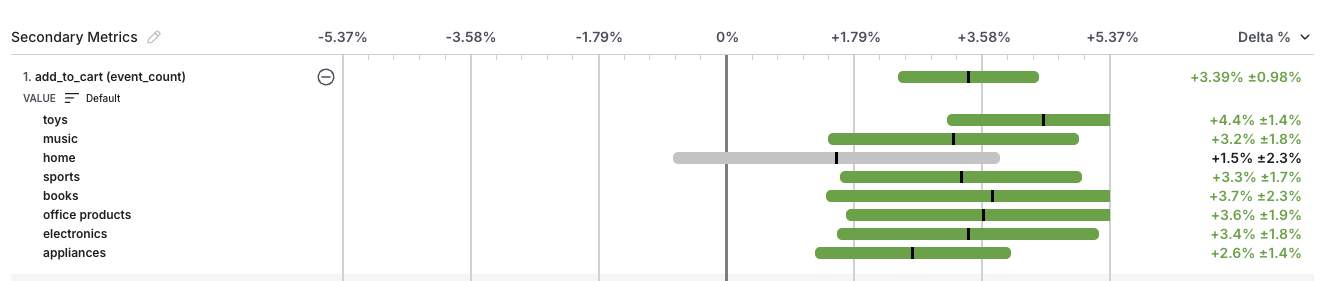
The experiment Scorecard shows the metric lifts for all Primary and Secondary metrics you set up at experiment creation.
Immediately post-experiment start
For up to the first 24 hours after starting your experiment (before the daily metric results run), Statsig calculates the Scorecard section hourly. This applies only to Statsig Cloud; for WHN projects, you must reload results on demand or set up a daily schedule. This real-time scorecard lets you confirm that exposures and metrics are being calculated as expected and debug your experiment or gate setup if needed.
Data in this early window is intended for diagnostics, not decision-making. The real-time view differs from daily results in the following ways:
- Metric lifts don't have confidence intervals
- No time-series view of metric trends
- No projected topline impact analysis
- No option to apply more advanced statistical tactics, such as CUPED or Sequential Testing
All of these are available in daily Results, which start showing in the next daily run.
Post-first day scorecard
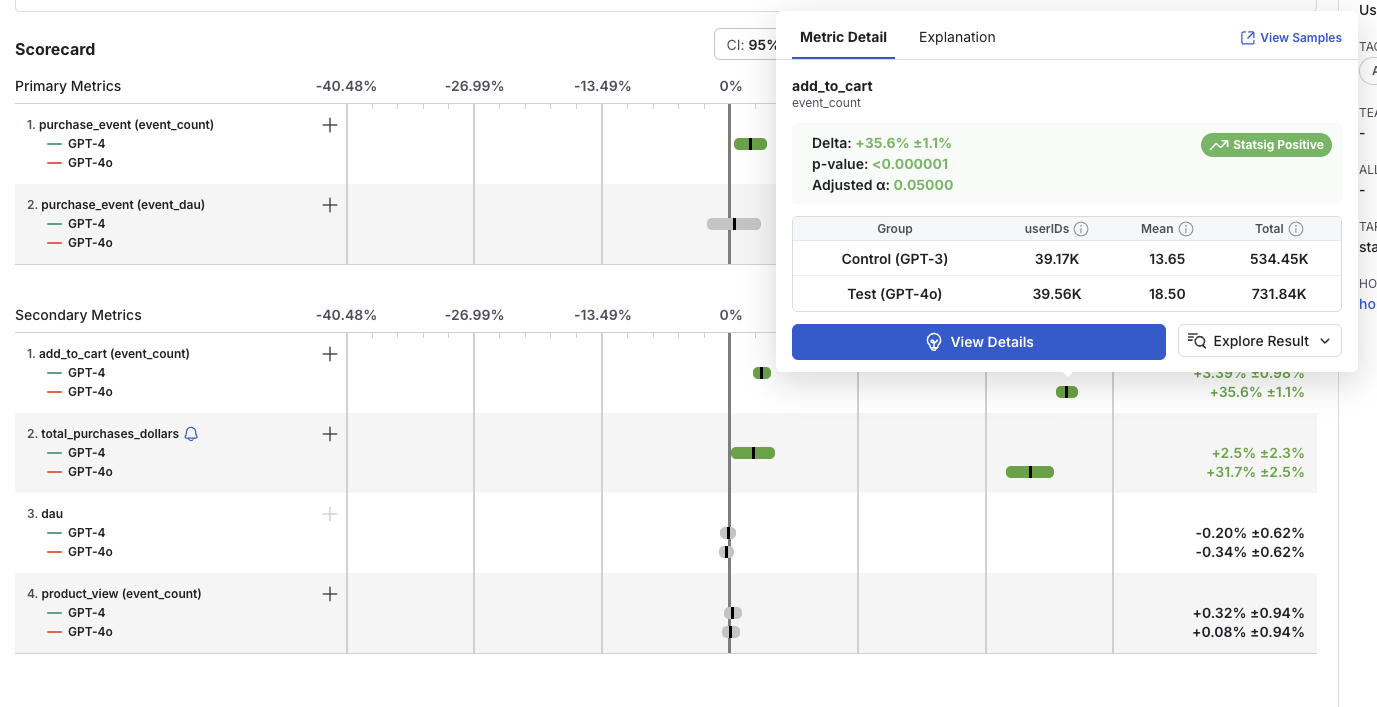
For every metric, Statsig shows you:
- The calculated relative difference (Delta %)
- The confidence interval
- Whether the result is statistically significant
- Positive lifts are green
- Negative lifts are red
- Non-significant results are grey
The formula for calculating lift is:
Delta(%) = (Test - Control) / Control
Confidence intervals are reported at the selected significance level (95% by default). In a typical two-sided Z-test, we show the confidence interval as +/- 1.96 * standard error.
Statsig automatically applies 99.9% winsorization to event_count, event_count_custom, and sum metrics. Winsorization caps extreme outlier values to reduce their impact on experiment results. For metrics added to the Scorecard or Monitoring Metrics sections of your experiment or gate, you can also apply optional statistical treatments such as CUPED (pre-experiment bias reduction) and sequential testing adapted confidence intervals. Refer to the stats engine documentation for more details.- Experiment results are computed for the first 90 days: By default, Statsig computes experiment results for only the first 90 days of your experiment. Statsig notifies you by email as you approach the 90-day cap. At that point, you can extend the compute window by 30 days at a time. If the experiment runs beyond the compute window, Statsig stops adding new users to the experiment's results, but analysis for users already exposed continues until you make a decision on the experiment.
This experiment result calculation window only affects whether a user is included in the experiment's analysis, and doesn't affect the treatment each user receives. New users still receive the experience for the group they get randomized into.
Experiment results views
There are several views for Scorecard metric lifts:
- Cumulative results (default view): Displays the aggregate difference between experiment groups and visualizes the corresponding confidence intervals.
- Table view: Displays the same data as the cumulative view but in a table format with additional fields.
- Daily results: Shows the difference between experiment groups aggregated based on days since start of experiment.
- Days since exposure: Shows the difference between experiment groups aggregated based on days since exposure to the experiment.
Cumulative results includes a detailed view on hover, where you can additionally view the raw statistics used in the metric lift calculations, as well as topline impact.

Dimensions
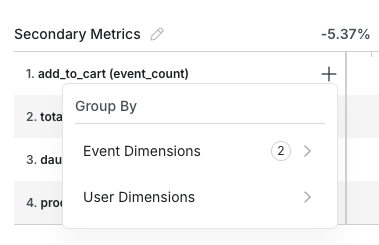
There are two ways to break down a given Scorecard metric: by a User Dimension or by an Event Dimension.
User dimensions
User Dimensions are user-level attributes that are either part of the user object you log, or additional metadata that Statsig extracts. Examples include operating system, country, and region.
You can create custom "explore" queries to filter or group by available user dimensions. For example, view results for users in the US, or for users on iOS grouped by country. Go to the Explore tab to draft a custom query.
Event dimensions
Event Dimensions are the value or metadata logged as part of a custom event used to define the metric. To see results for a metric broken down by categories specific to that metric, specify the dimension in the value or metadata attributes when you log the source event. For example, when you log a "click" event, you can also log the target category using the value attribute. Statsig automatically generates results for each category in addition to the top-level metric.To see breakdowns for all categories within a metric, click on the (+) sign next to the metric.
Significance level settings
You can adjust these settings at any time to view Scorecard results at different significance levels.
- Apply Benjamini-Hochberg Procedure per Variant: Reduces the probability of false positives by adjusting the significance level for multiple comparisons. Refer to Benjamini-Hochberg Procedure for details.
- Confidence Interval: Changes the confidence interval displayed with the metric deltas. Choose lower confidence intervals (for example, 80%) when tolerance for false positives is higher and fast iteration with directional results is preferred over longer experiments with greater certainty.
- CUPED: Toggle CUPED on or off using the inline settings above the metric lifts. This setting applies only to Scorecard metrics; Statsig doesn't apply CUPED to non-Scorecard metrics.
- Sequential Testing: Applies a correction to p-values and confidence intervals to reduce false positive rates when evaluating results before the target completion date, which mitigates the increased false positive rate caused by early result evaluation. Toggle Sequential Testing on or off using the inline settings above the metric lifts. This setting is available only for experiments with a set target duration.

Restarting results

If your experiment has stopped computing results, you can resume updates by clicking the Restart button. Understand how Restart behaves before proceeding:
- A Restart isn't a Reset of your experiment. A Restart doesn't re-salt (re-randomize) units in your experiment, and all users continue to receive the same group assignments.
Statsig begins computing experiment results from the restart point, so your metric results start over. Old results may still be available in timeseries and explore query views, but Statsig doesn't carry them forward or update them.
Your Cumulative Exposures chart updates based on new exposures, but the duration of the pause in computations affects whether the chart starts over from zero or your exposure count includes past exposures.
To avoid needing a Restart, extend experiments actively while they are running. Look out for email alerts from Statsig and check your experiments regularly.
Was this helpful?