Pulse
Drill down into Statsig experiment results by user segment, dimension, or time period to understand which sub-populations drive aggregate metric changes.
Metric tooltip
When you hover over a metric in Pulse, Statsig shows a tooltip with key statistics and deeper information.
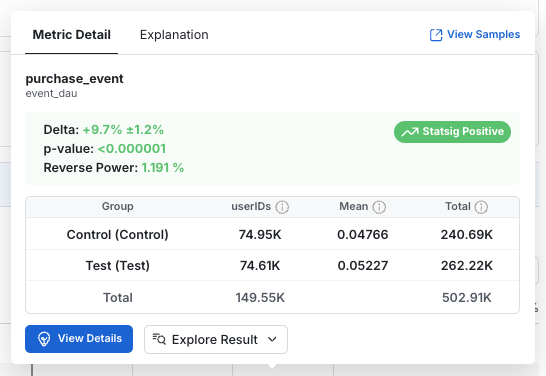
- Group: The name of the group of users. For Feature Gates, the "Pass" group is considered the test group while the "Fail" group is the control. In Experiments, these are the variant names.
- Units: The number of distinct units included in the metric. E.g.: Distinct users for user_id experiments, devices for stable_id experiments, etc.
- Mean: The average per-unit value of the metric for each group.
- Total: The total metric value across all units in the group, over the time period of the analysis.
Calculation details
| Metric Type | Total Calculation | Mean | Units |
|---|---|---|---|
| event_count | Sum of events (99.9% winsorization) | Average events per user (99.9% winsorization) | All users |
| event_user | Sum of event DAU (distinct user-day pairs) | Average event_dau value per user per day. Statsig calls this "Event Participation Rate" because it represents the probability a user is DAU for that event. | All users |
| ratio | Overall ratio: sum(numerator values)/sum(denominator values) | Overall ratio | Participating users |
| sum | Total sum of values (99.9% winsorization) | Average value per user (99.9% winsorization) | All users |
| mean | Overall mean value | Overall mean value | Participating users |
| user: dau | sum of daily active users | Average metric value per user per day. The probability that a user is DAU | All users |
| user: wau, mau_28day | Not shown | Average metric value per user per day. The probability that a user is xAU | All users |
| user: new_dau, new_wau, new_mau_28day | Count of distinct users that are new xAU at some point in the experiment | Fraction of users that are new xAU | All users |
| user: retention metrics | Overall average retention rate | Overall average retention rate | Participating users |
| user: L7, L14, L28 | Not shown | Average L-ness value per user per day | All users |
p-Value
In Null Hypothesis Significance Tests, the p-value is the probability that such an extreme difference arises by random chance when the experiment has no actual effect. A low p-value indicates the observed difference is unlikely to be due to random chance. In hypothesis testing, a p-value threshold determines which results are due to a real effect and which are plausibly due to random chance. (p-value calculation)Reverse power
Reverse power is the smallest effect size that an experiment can reliably detect in its current state (some studies refer to this value as ex-post MDE). Statsig calculates it from the sample size and standard error from the control group. Importantly, reverse power does not depend on the observed effect size. In practice, reverse power answers such questions like: given how the test actually played out, what is the smallest effect we have sufficient power (typically 80%) to detect?
For a two-sided test, the reverse power for a given metric X is computed using the following equation:
For a one-sided test, the reverse power for a given metric X is computed using the following equation:
- is the mean metric value across control users
- is the population variance of delta
- are the observed number of units in the control group
- is the standard Z-score for the selected power. Typically = 0.8 and = 0.84
- and are the standard Z-scores for the selected significance level in a two-sided test and in a one-sided test.
You can enable reverse power as an optional feature. To manage it, go to Settings > Product Configuration > Experimentation > Organization and toggle it on or off.
Detailed view
Select View Details to access in-depth metric information. The detailed view contains three sections:
- Time Series: How the metrics evolve over time
- Raw Data: Group-level statistics
- Impact: How the experiment impacts the metric
Time series
In this view, select and drag to zoom in on different time ranges. The drop-down offers three types of time series:
Daily: The metric impact on each calendar day without aggregating days together. This is useful for assessing day-over-day variability and the impact of specific events. This is the recommended time series view for Holdouts, because it highlights the impact over time as new features are launched.
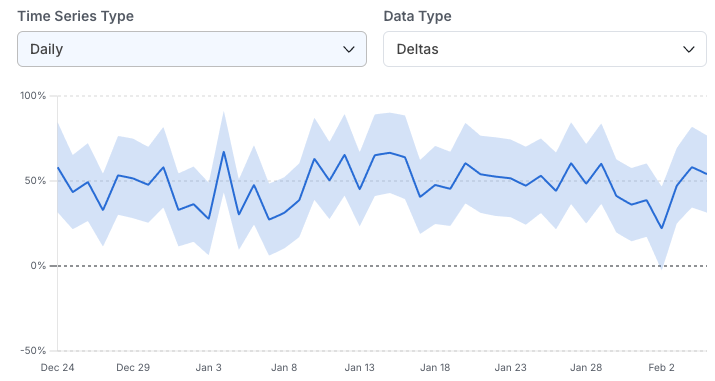
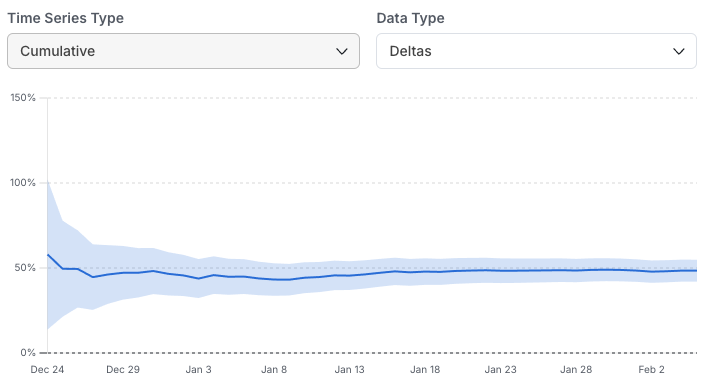
Cumulative: Shows the cumulative metric impact from the start of the experiment over time. This is useful for observing trends and seeing how your confidence interval changes over time.
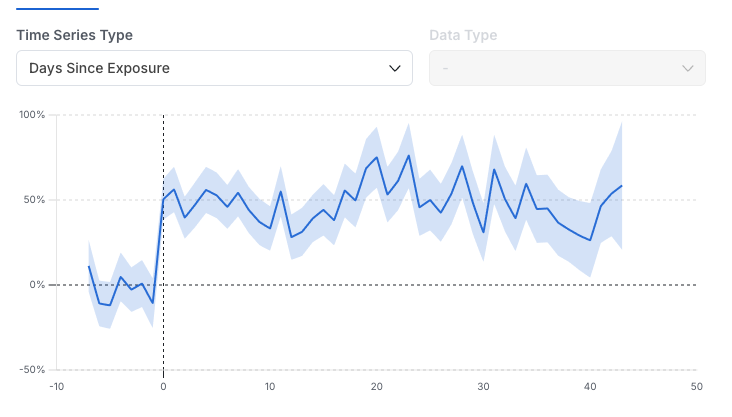
Days Since Exposure: Shows the metric impact based on how long a user has been in the experiment. Daily data for each user is aligned by the day the user entered the experiment (Day 0, Day 1, and so on), not by calendar date. This lets you distinguish early (novelty) effects from long-term effects. This view also shows pre-experiment data, which identifies biases between groups before the experiment started. Such biases can arise from random chance or from an issue in the random assignment process.
Raw data
This view shows the group-level statistics needed to compute the metric deltas and confidence interval. These include Units, Mean, and Total (described above), as well as the Standard Error of the mean (Std Err). Refer to the statistical calculations reference for details.Impact
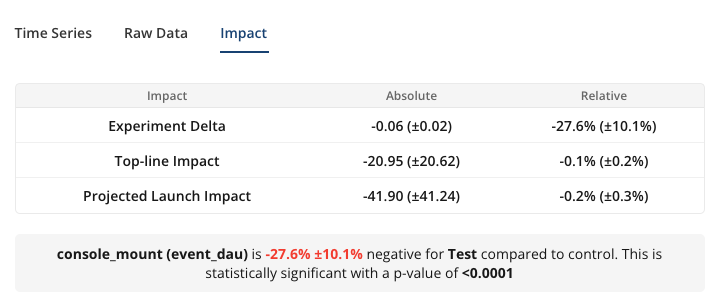
- Experiment Delta (absolute): The absolute difference of the Mean between test groups i.e. Test Mean - Control Mean. Statsig shows the p-value to indicate whether the observed absolute difference is statistically significant.
- Experiment Delta (relative): Relative difference of the Mean i.e. 100% x (Test Mean – Control Mean) / Control Mean.
- Topline Impact: The measured effect that experiment is having on the overall topline metric each day, on average. Computed on a daily basis and averaged across days in the analysis window. The absolute value is the net daily increase or decrease in the metric, while the relative value is the daily percentage change.
- Projected Launch Impact: An estimate of the daily topline impact Statsig expects if a decision is made and the test group is launched to all users. This takes into account the layer allocation and the size of the test group. Assumes the targeting gate (if there is one) remains the same after launch.
FAQs about topline impact
Why is the projected launch impact smaller than the relative experiment delta?
An experiment can impact only a subset of the user base that contributes to a topline metric. The relative experiment delta observed is effectively diluted when measured against the topline metric value.
For example: consider a top-of-funnel experiment on the registration page. Among users who visit this page, the treatment leads to more sign-ups and a 10% lift in daily active users (DAU). However, the topline DAU metric includes other user segments outside of the experiment, such as long-term users who don't visit the registration page. A 10% lift in the test vs. control comparison may amount to only a 1% increase in overall DAU.
How can the topline impact be higher than the experiment delta?
The topline impact can be higher or lower than the experiment delta because Statsig computes the two values differently and they have different meanings.
Experiment deltas are based on unit-level averages: Statsig computes the mean value of the metric for each user across all days, then averages it to obtain the group mean. Statsig computes the topline impact daily based on the total pooled effect from all users, then averages it across days to show the daily impact.
Statsig computes topline impacts this way because most metrics are tracked on a daily basis and the topline value is an aggregation across all users rather than a user-level average. For experiment analysis, best practice is for the analysis unit to match the randomization unit, so metrics are aggregated at the unit level first before computing experiment deltas.
Was this helpful?