Bayesian Experiments
Learn about Bayesian A/B testing on Statsig, including informative priors and implementation details.
How Bayesian testing works in Statsig
Bayesian mode analyzes your experiment with Bayesian statistics. This mode lets you factor in prior beliefs about the treatment effect and report results as a chance to beat control and expected loss. Non-technical audiences often find these terms more intuitive than the p-values that frequentist analysis uses by default. Experiments are frequentist by default; to switch to Bayesian mode, go to Advanced Settings.
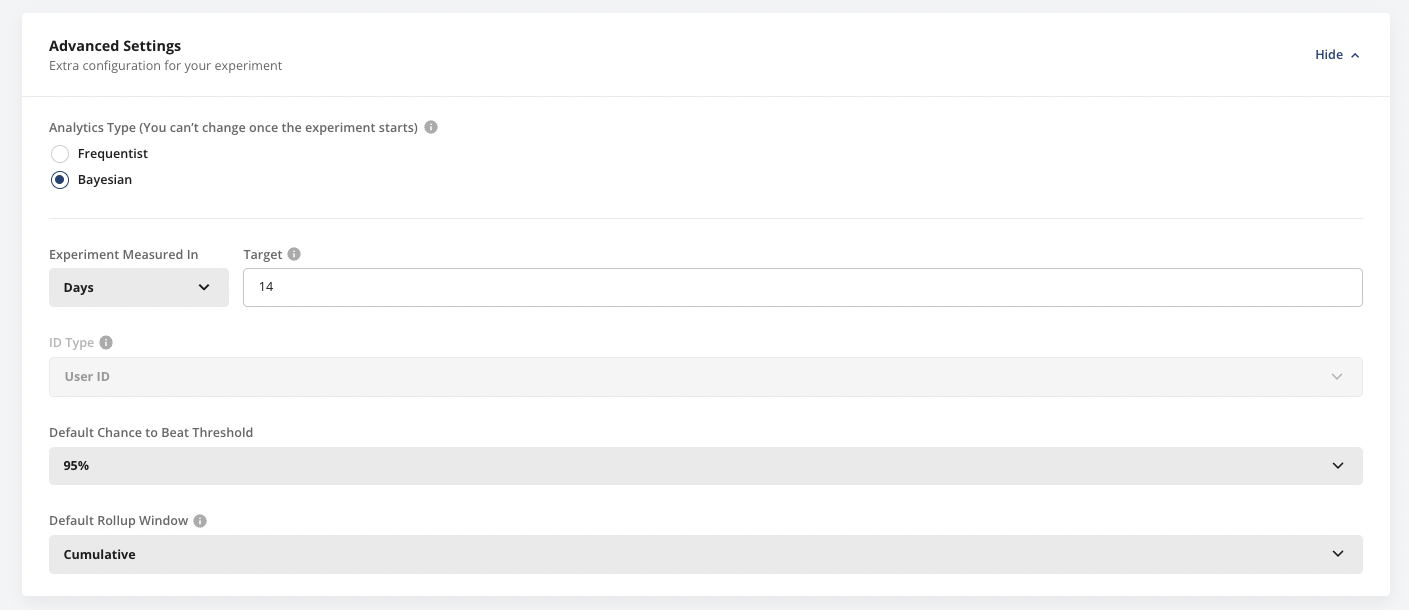
You can't modify the experiment type after the experiment starts.
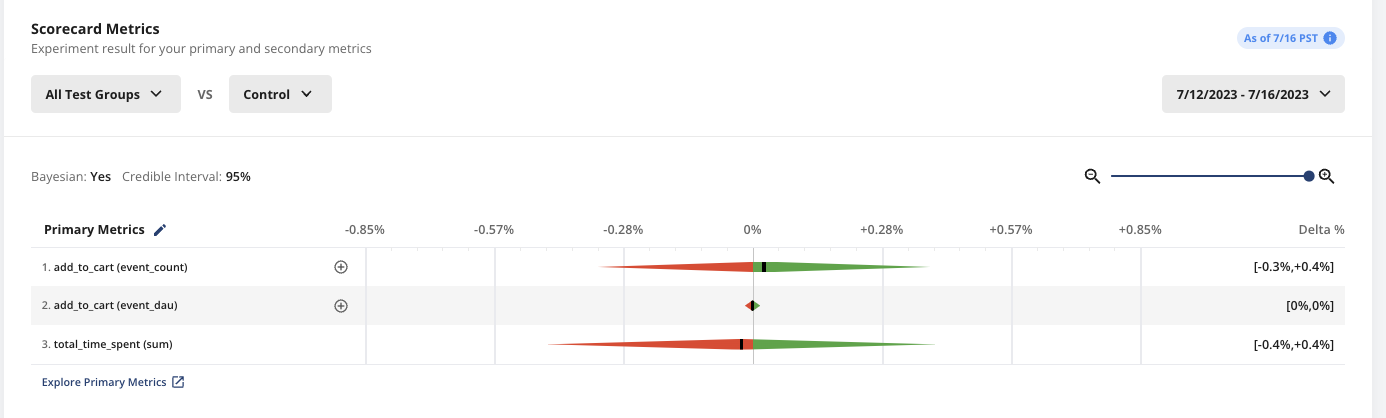
Deep-dive analysis reflects Bayesian statistics.
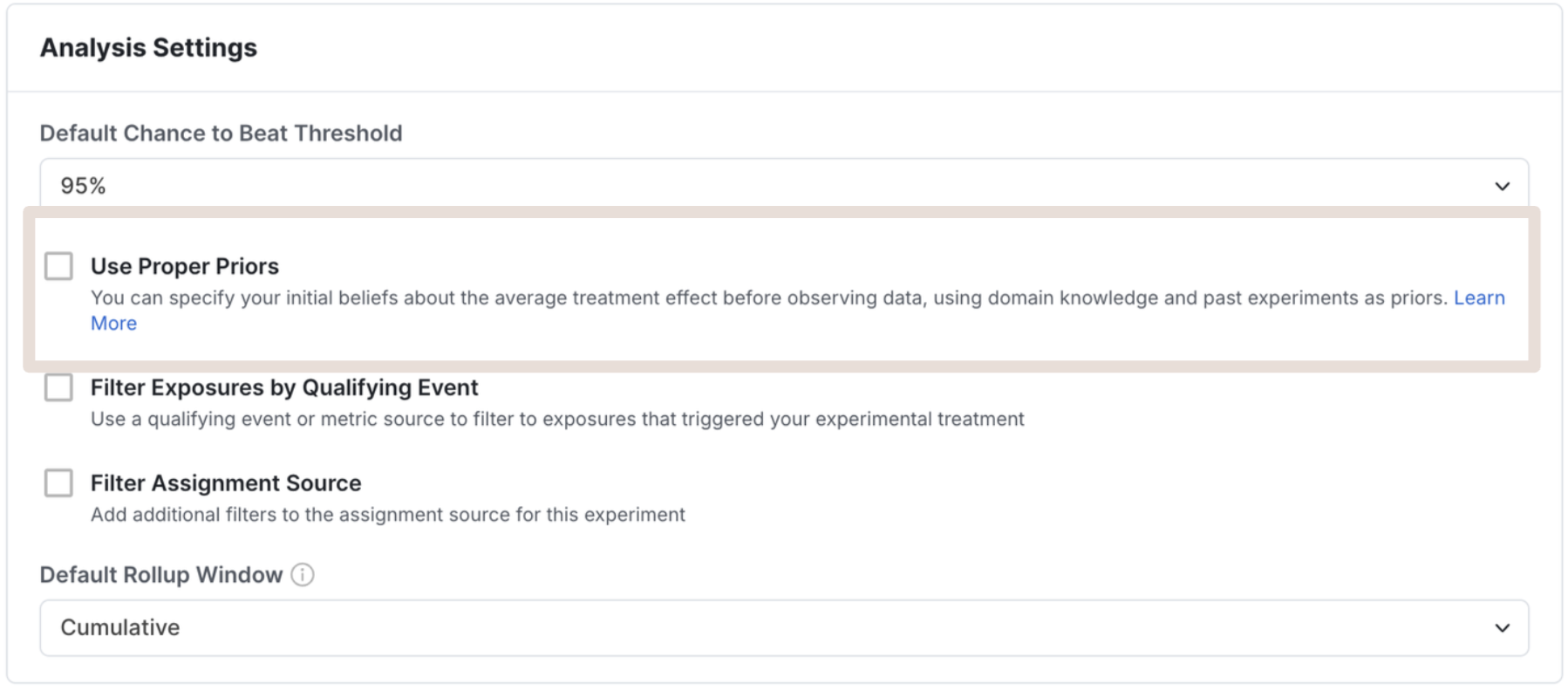
Informed Bayesian
Bayesian experiments let you specify a prior belief on the relative average treatment effect. Statsig combines the prior distribution with the observed data to display prior-adjusted results. To enable prior-adjusted results, select the "use informative priors" option.
Drawing the correct prior distribution from historical data
When you use Bayesian mode with informative priors, your organization must understand what influence the priors have over your experimental results. Your organization must also establish a reliable prior based on domain knowledge. Use these patterns to derive priors:
- You can use the of past experiments with a similar setup and population as your prior mean. You can use the standard deviation, or a multiple of it, as the prior standard error.
- You can also use the as your prior standard error.
Implementation details
Denote as the prior distribution, where is the average treatment effect and is the standard error. Similarly, as the observed distribution.
Statsig then calculates the posterior distribution as
If you don't specify a prior, Statsig represents the as .
Bayesian statistics glossary
Bayesian A/B tests use different terminology from the frequentist framework. These terms are often more intuitive for communicating results to non-technical audiences.
| Term | Definition |
|---|---|
| Credible Interval | The interval that contains the true parameter at the given probability |
| Chance to Beat | The probability that the test is better than control |
| Expected Loss | The average potential risk if you ship the test variant |
Was this helpful?