Stratified Sampling
Learn how stratified sampling reduces variance and improves experiment reliability in low volume or high variance scenarios.
What is stratified sampling
Stratified sampling involves dividing the entire population into homogeneous groups called strata (plural for stratum). Random samples are then selected from each stratum. For example, if you had XS and XL customers and randomized them into two groups (Control and Test), you would want both Control and Test to be balanced across XS and XL customers. You can also stratify based on a metric such as Revenue/User.
With large numbers, randomization typically solves this balance problem. However, in B2B scenarios and other relatively low-volume or high-variance scenarios, stratified sampling ensures this balance. Statsig supports both automated and manual stratified sampling. In tests where a tail-end of power users drive a large portion of an overall metric value, stratified sampling meaningfully reduces false positive rates and makes results more consistent. In Statsig's simulations, this approach produced around a 50% decrease in the variance of reported results.
Automated stratified sampling
How it works
The Statsig SDKs use a salt to randomize or bucket experiment subjects (learn more). When you enable stratified sampling, Statsig tries n different salts (100 by default) and evaluates how balanced your groups are. Statsig evaluates this balance based on either a metric you select or an attribute you provide describing your experiment subjects, then picks and saves the best salt. Learn more.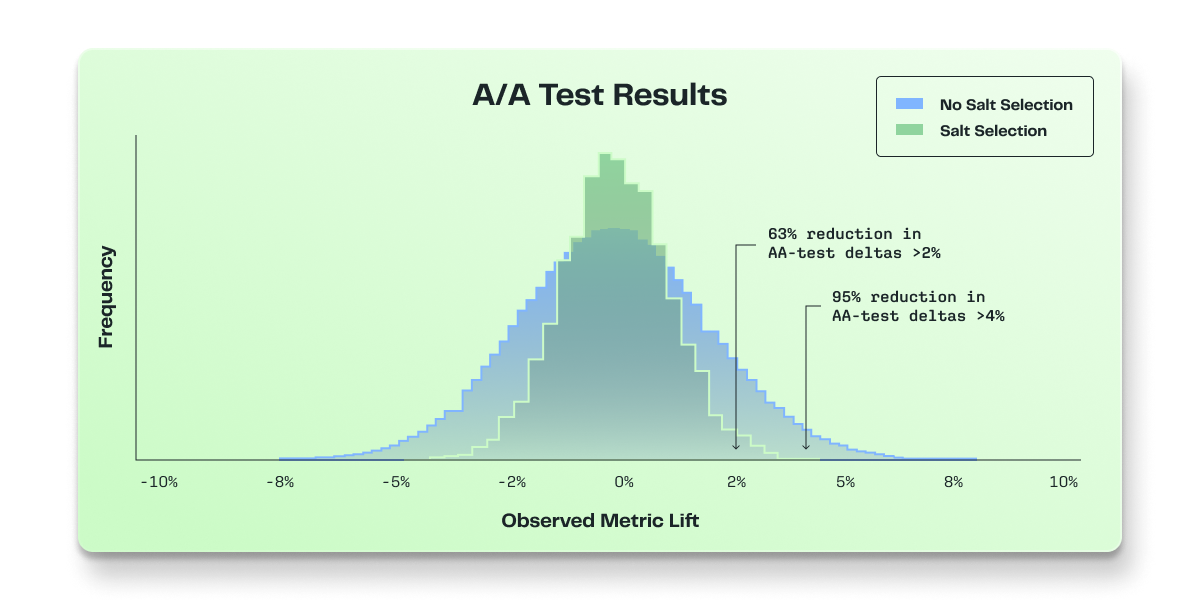
The selection space for the salts is large enough that stratifying multiple experiments on the same metric will not result in overlap. In Statsig's simulations, the groups were as independent as expected, which matched the literature on this topic.
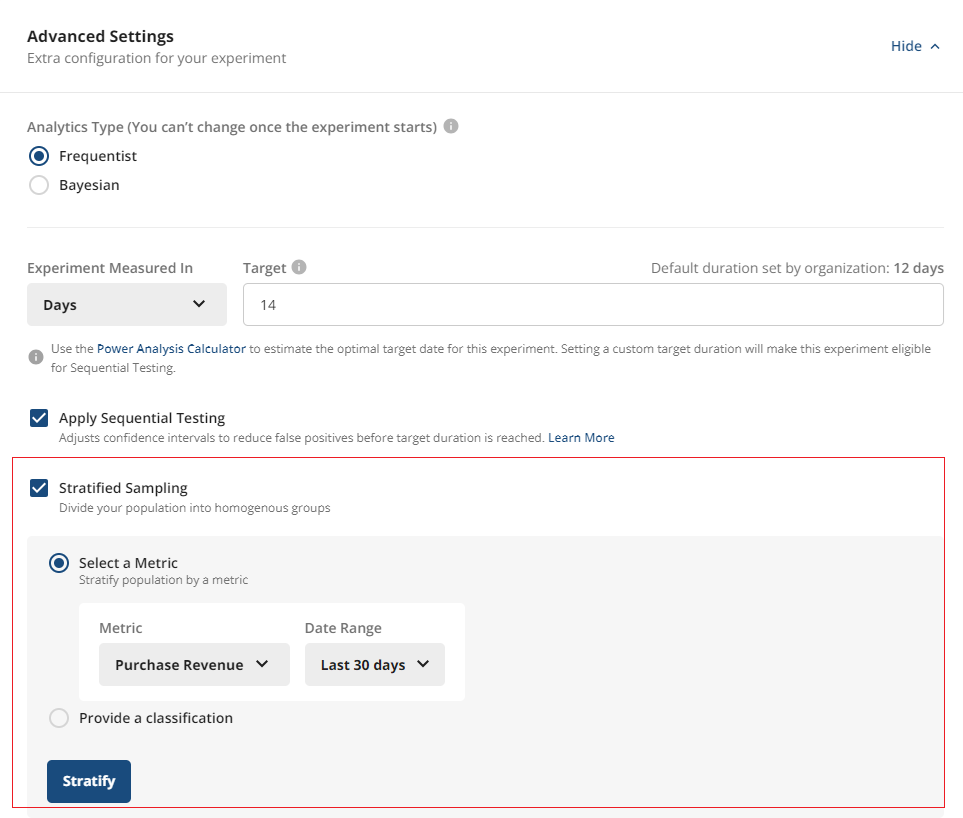
Enabling stratified sampling
You can enable this on an experiment under Advanced Settings on the experiment setup page. There are two ways to stratify on Statsig. If you choose a metric to stratify on, Statsig uses that metric to balance the groups.
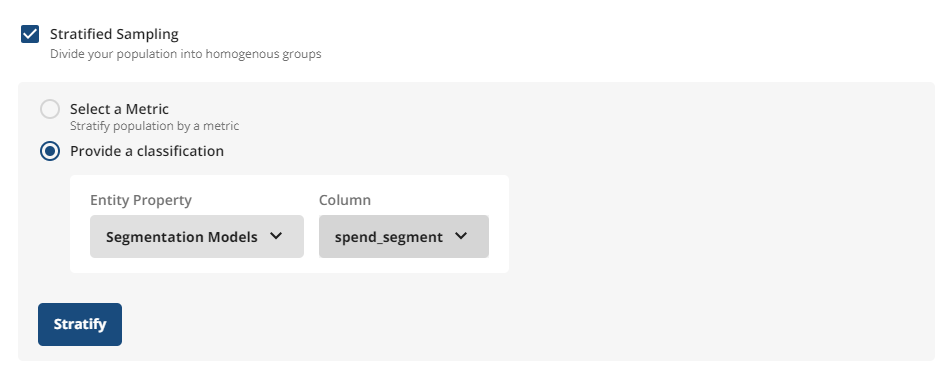
If you instead choose an attribute or a classification (for example, S, M, L, XL), Statsig uses that to balance the groups.
- On Statsig Cloud, you'll upload a CSV (in Beta)
- On Statsig Warehouse Native, you'll use Entity Properties
After you select the Stratify button, Statsig analyzes a set of salts and picks the best one.
FAQ and best practices
What population is used when balancing?
- When evaluating salts, Statsig computes balance using pre-experiment data for the entire targeted population of the experiment’s unit type (for example, all
userIDs or allcustomerIDs) over the selected lookback window. There is no filtering on exposure because the experiment has not started yet.
- When evaluating salts, Statsig computes balance using pre-experiment data for the entire targeted population of the experiment’s unit type (for example, all
How are new units handled after stratification?
- Units that were not present in the pre-experiment data are still assigned deterministically by the chosen salt, i.e., effectively at random with respect to the balancing metric. They do not influence the salt selection and may introduce some drift from the initial balance.
Should I use stratified sampling for every experiment?
- Not necessarily. Stratified sampling is most useful when you expect imbalance due to heterogeneous units (for example, “whales”) or skewed metrics. The tradeoff is time and compute cost that scales with the number of units and adds steps before starting an experiment. If you do not expect meaningful imbalance, a standard random split is generally recommended.
Does salt evaluation assume 100% allocation? What about running at less than 100%?
- Yes. All candidate salts are evaluated assuming 100% of the targeted population is allocated. If you run the experiment at an allocation below 100%, random sampling of that subset can reintroduce imbalance (for example, by chance, some high-impact units may fall disproportionately into one arm). For the period you care most about inference, prefer 100% allocation to preserve the intended balance. Lower allocations are best used briefly for safe rollouts rather than for the full experiment duration.
Across candidate salts, is it the same set of users being evaluated?
- Yes. Candidate salts are assessed over the same targeted population; only the randomization induced by the salt changes.
How long does stratification take?
- Duration depends on the number of units and the metric/source being queried. There is no fixed SLA; larger populations take longer.
Manual assignment for stratified sampling
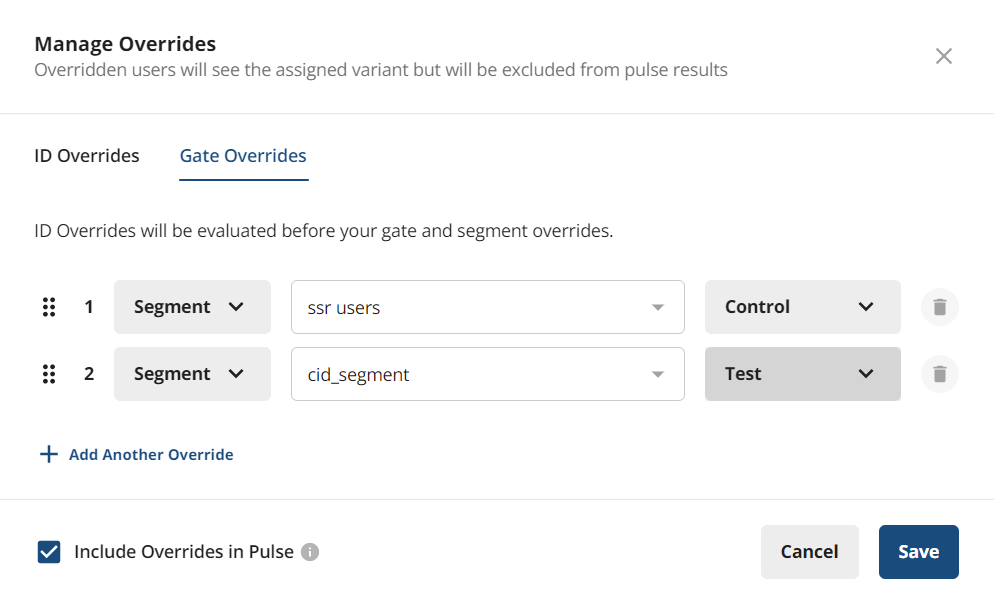
When setting up an experiment, you can configure overrides (for example, force user X or Segment A into Control, force user Y or Segment B into Test). Overrides are intended for testing; overridden users are excluded from experimental analysis in Pulse results. To use manual assignment for stratified sampling, select the Include Overrides in Pulse checkbox. This includes manually overridden users in each variant in all metric lift analyses. You can configure 100% of experiment participants into your test variants manually, or configure some subset of participants into variants manually and randomly assign the remainder.
While you can add overrides for an ID type that is different than the ID type of the experiment, those ID evaluations will not be resolved to the id type of the experiment and will not contribute to pulse results.
When you use the Statsig SDK for assignment, it handles randomization. When you control assignment of users, you're responsible for making sure users are balanced across experiment groups.
Related resources
Morgan and Rubin 2012 walks through the history, the philosophy, and the proofs of re-randomization, especially how re-randomization reduces the randomization variance of the difference in means. It's worth noting that "Standard asymptotic-based analysis procedures that do not take the re-randomization into account will be statistically conservative" was called out in the paper. However, to maintain consistent and comparable results across different methods, Statsig stays conservative with the t-test.Lin & Ding 2019 is another interesting read for your reference.Was this helpful?