Switchback Tests
Learn about switchback testing methodology and how to set up switchback experiments for marketplaces and network effect scenarios.
What is switchback testing?
Switchback tests are an alternative experiment form in which an entire population switches back and forth between test and control treatments on a set cadence, rather than being split and evenly divided between test and control for the duration of the experiment.
Switchback tests are particularly common in marketplaces. Running a traditional A/B test on one side of the marketplace can have unintended consequences on the rest of the marketplace due to network effects, which affect experiment results.
Another common use case for switchbacks is when applying different variants to different users isn't feasible for fairness, legal, or logistical reasons.
Switchback tests are often carried out across multiple "buckets", typically regions or other defined groups that are flipped between test and control treatments over the course of the experiment.
Example
Consider a rideshare platform that wants to test pricing. The initial approach splits riders into two groups: one with a higher price and one with a lower price.
Riders with the lower price request rides at a significantly higher rate, consuming all available driver supply in a given area. This leaves riders with higher prices facing not only a higher ride estimate but also longer ETAs, making them even less likely to request a ride.
The experiment results become unclear: the decreased ride request rate in the higher-price group could be caused by the higher prices or by the longer ETAs. The experimental design has introduced bias into the results.
A switchback test resolves this. Instead of splitting users, 100% of riders and drivers in a given metro switch in and out of the new pricing plan hourly. The test then measures the impact on overall ride request rates during hours when prices were higher versus lower.
Switchback testing on Statsig
Methodology
The switchback testing methodology for computing results consists of 3 steps:
- Attribute events to the corresponding switchback bucket, where each bucket is defined by the time window and grouping attribute.
- Calculate the variant-level and bucket-level metrics based on the attributed events.
- Calculate the difference in means between test and control. Use bootstrapping to obtain the confidence intervals.
Event attribution
Attribution of events to a particular bucket is based on the timestamp and unit_id of the exposure, the length of the attribution window, and the timestamp of subsequent events for that unit_id.
For example: User 123 is exposed to bucket A at 9:15 AM. The test has an attribution window of 90 minutes. All events triggered by user 123 between 9:15 AM and 10:45 AM are included in the metric calculations for bucket A.
Bucket-level metrics
Once Statsig has all the events corresponding to a bucket, it calculates the scorecard metrics derived from these events.
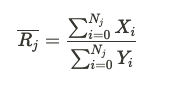
For sum and count metrics, Statsig uses the mean value per unit exposed to that bucket.
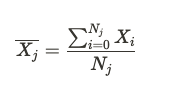
Variant-level metrics
Statsig calculates overall metric means for test and control by aggregating values across all buckets in that variant. If there are M buckets in the test group, the mean value of a ratio metric is given by:
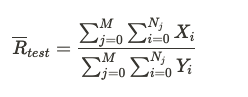
The mean of a sum or count metric would be:
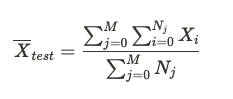
Deltas and confidence intervals
The treatment effect is calculated as:
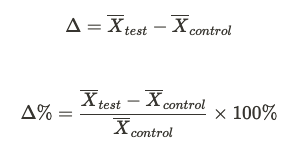
The bootstrapped confidence intervals are obtained as follows:
- Collect a bootstrap sample with replacement from the set of test buckets and separately from the set of control buckets.
- Calculate the difference in means between test and control samples.
- Repeat steps one and two 10,000 times to produce a distribution of metric deltas.
- The 95% confidence interval is the range from the 2.5% quantile to the 97.5% quantile of that distribution. In general, the confidence interval with significance level is given by:
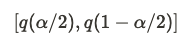
Setup
To set up a switchback test on Statsig, when you create an experiment tap Advanced Settings → Experiment Type and select "Switchback Test".
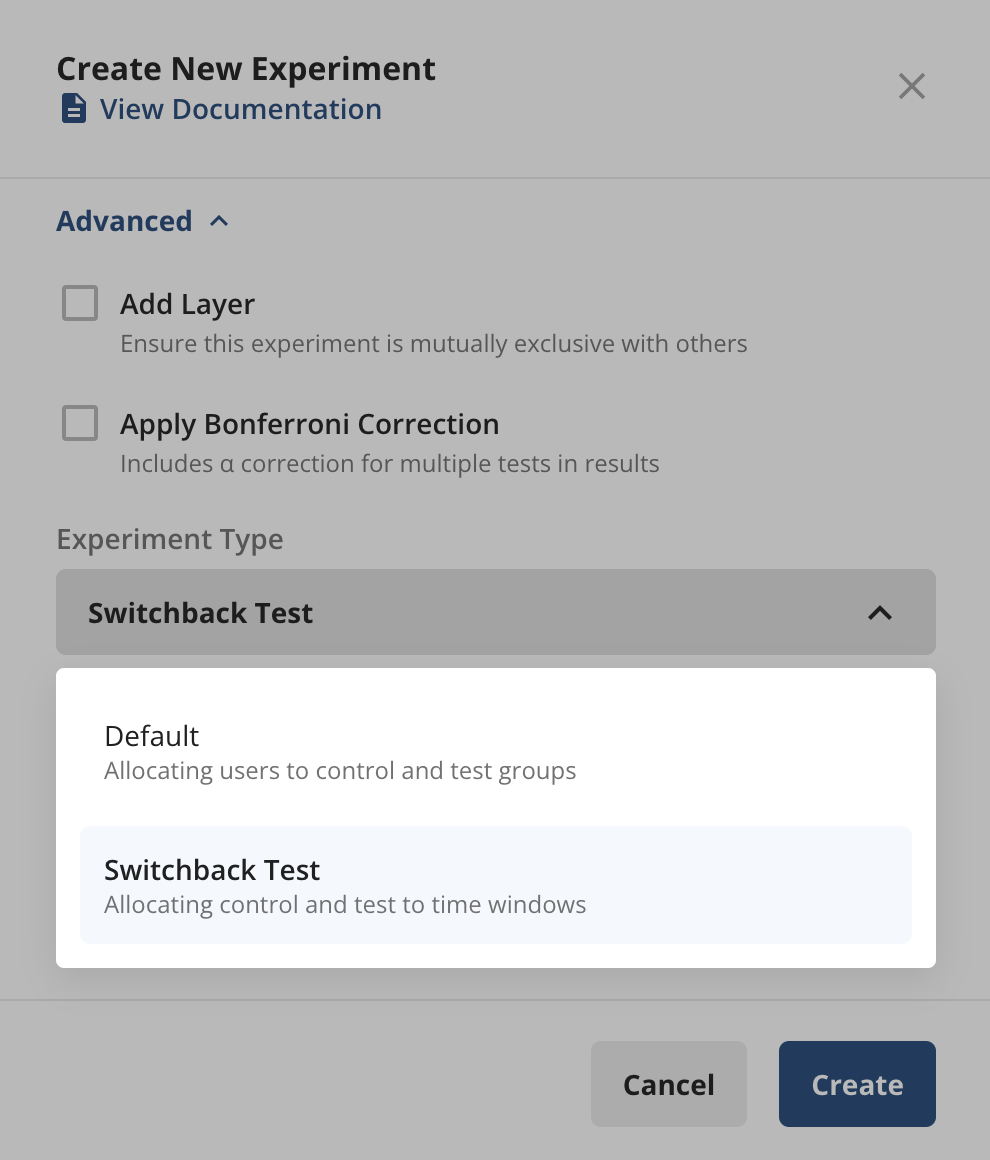
Switchback test configuration adds two new aspects to the standard experiment setup:
- Targeting: The defined population(s) you run your experiment on.
- Schedule: The switching frequency and starting treatments for different pre-defined populations.
There are two ways to define targeting:
- Targeting Gate: Specify a targeting gate to define your target experiment population, the same as any other experiment on Statsig.
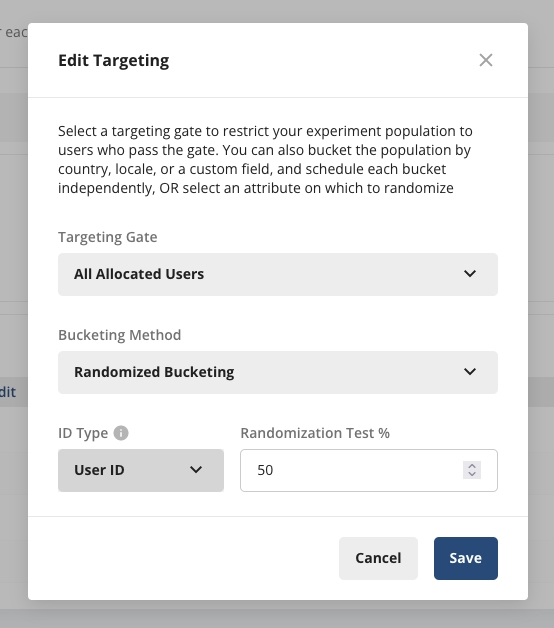
- Bucketing Method: Bucket users based on either pre-defined buckets or randomized across an ID type.
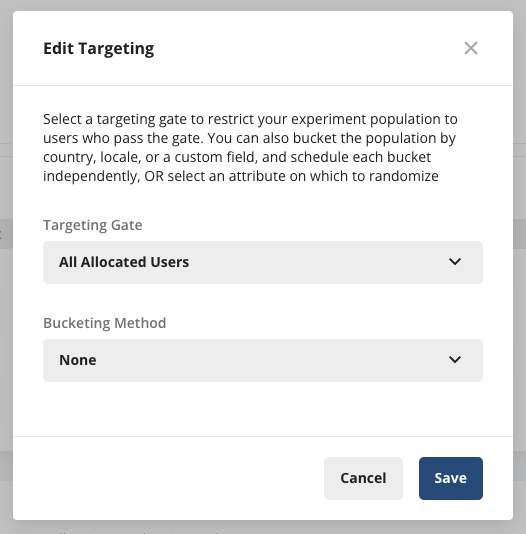
Buckets let you specify pre-defined buckets, such as Country, Locale, or a Custom Field you log. Use this option when you have a few pre-defined populations you want to switch in and out of Test/Control over the course of the experiment.
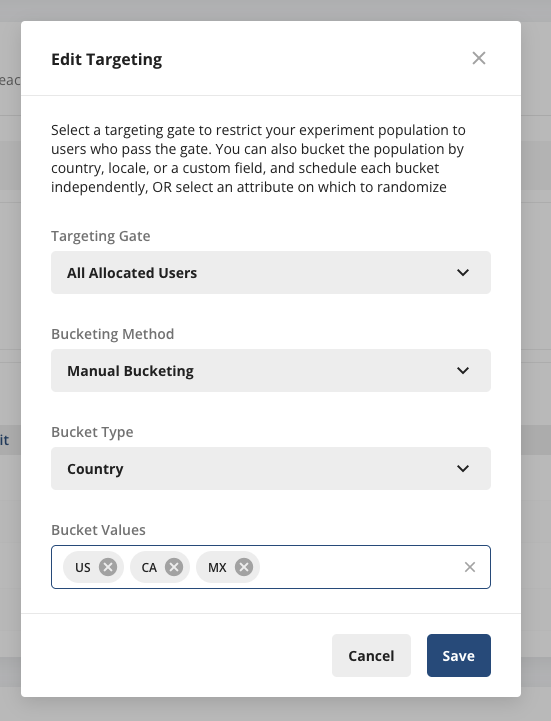
ID Type lets you specify an ID type to randomize across. For example, choosing a custom ID such as CityID automatically randomizes different CityIDs across Treatment/Control over the different switchback windows. Use this option when you have a very large or dynamic number of experiment units to randomize across.
Depending on which bucketing method is selected, the Schedule section of experiment setup lets you configure:
- Start time
- Duration (in days)
- Assignment window size (in minutes)
- Burn-in/ burn-out periods (in minutes)
- (Pre-defined bucketing only) Starting phase (treatment group) for each bucket
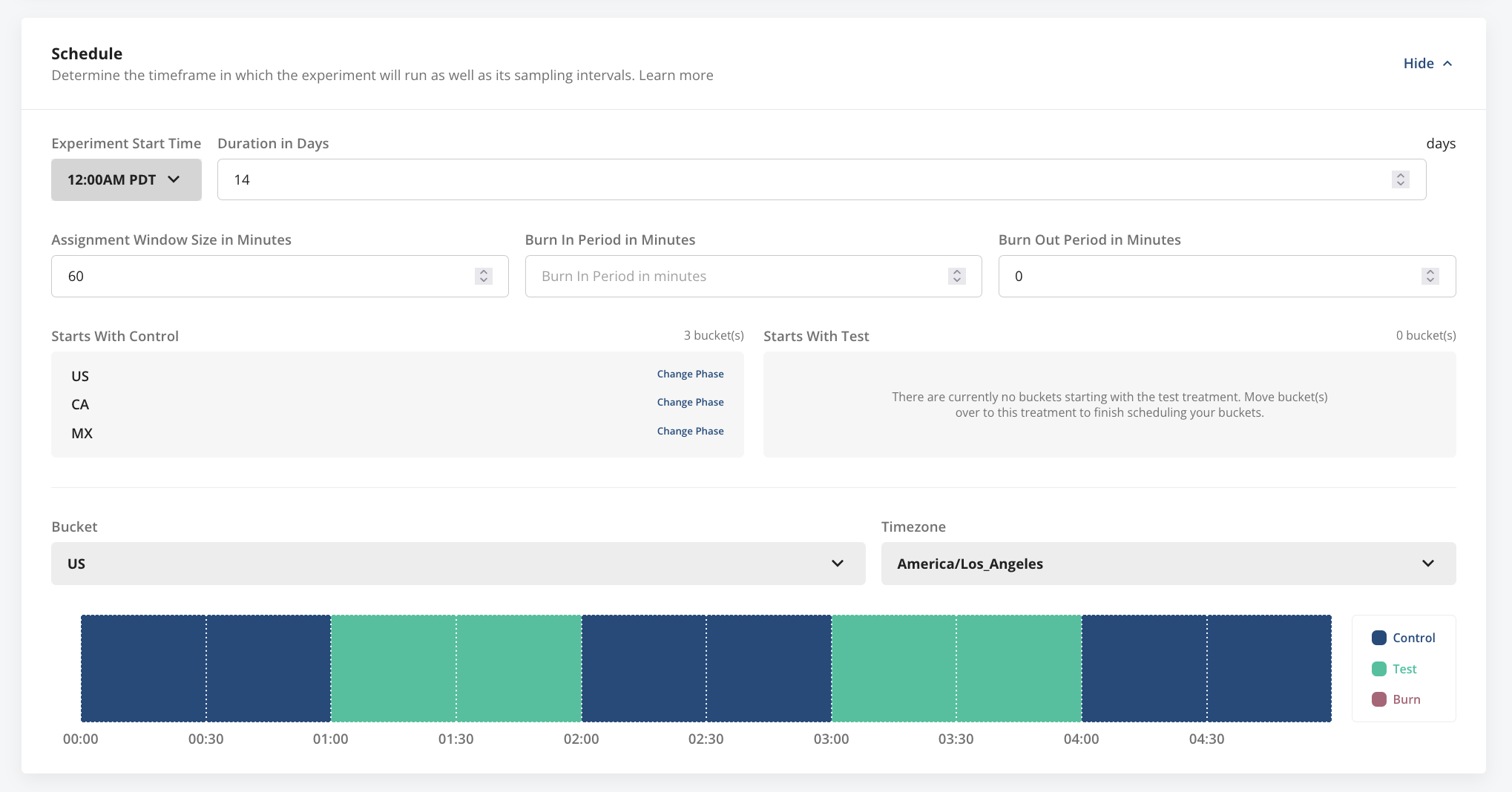
Burn-in/burn-out periods let you define time intervals at the start and end of your switchback windows to discard exposures from analysis. Use these when there are risks of bleed-over effects from the previous treatment while a population is switching between test and control.
Reading results
Diagnostics and Pulse metric lift results for switchback tests resemble Statsig's traditional A/B tests, with a few differences:
- No hourly Pulse: Because a switchback experiment starts with all-Test or all-Control exposures, hourly Pulse is disabled until there is a meaningful amount of data. Use the Diagnostics tab in the meantime to verify checks are arriving and bucketing as expected.
- No time-series: The Daily and Days Since First Exposure time-series aren't available for switchback tests. The bootstrapping methodology requires pooling all available days together to achieve sufficient statistical power.
- No dimension breakdown: Breaking down a metric by user property or event property isn't available for switchback tests.
- Advanced statistical techniques: CUPED and Sequential Testing aren't yet available for switchback tests.
Was this helpful?