Frequentist Sequential Testing
Learn how sequential testing addresses the peeking problem in A/B tests and enables early decision making with statistical rigor.
What's the problem with looking early in a "standard" A/B test
Traditional A/B testing best practices (t-tests, z-tests, etc.) require that the readout of experiment metrics occur only once, when you reach the target sample size. Reaching the target sample size means you have reached your design duration and have the sample size you need. This approach is a "Fixed Horizon Test". When you design an experiment, you set the number of units you want to observe and commit to analyzing results only after the dataset is complete.
Sequential testing lets you look at results and make valid early decisions before you reach that target sample size. A fixed-horizon analysis instead requires you to wait and analyze the data only after the data is complete.
Continuous experiment monitoring ("peeking") to make decisions results in inflated false positive rates (the peeking problem). These rates can be much higher than the expected rate at the significance level you want.
How peeking increases decision error rates
Continuous monitoring leads to inflated false positives because any time you consider ending an experiment early, you risk making an incorrect conclusion. At the core of a standard hypothesis test, you decide whether to "accept the null" hypothesis or "reject the null" hypothesis and accept the alternative. Any time you look early and allow the possibility of an early decision, you're potentially rejecting the null hypothesis even when the null hypothesis is correct.
Why early results can be misleading
Metric values and p-values always fluctuate to some extent due to noise during any experiment. Results can move into and out of statistical significance because of this noise, even when there is no real underlying effect. Noisy fluctuations result from random unit assignment and unpredictable user behavior, and you can't eliminate them entirely. Noise levels vary by test, depending on what you're testing and who your users are. Tests also vary over time in the amount of noise they see, as adding more users and observing them longer tends to help random fluctuations even out.
Peeking introduces selection bias when it causes an experimenter to adjust the readout date. When an experimenter makes any early decision about results (for example, "is the result stat-sig; can we ship a variant early?"), the chances increase that the decision relies on a temporary snapshot of results. These results always fluctuate. The experimenter is potentially selecting a stat-sig result that wouldn't appear if you analyzed the data only once at the full, pre-determined completion of the experiment. In frequentist A/B test procedures, early decisions can only increase the false positive rate (declaring an experimental effect when there is none). This increase occurs even when the intention is to make a less-biased decision.
How Sequential Testing works for an A/B test
In Statsig's implementation of Sequential Testing, Statsig automatically adjusts p-values and confidence intervals for each preliminary analysis window. These adjustments compensate for the increased false positive rate associated with peeking, as the Results tab shows:
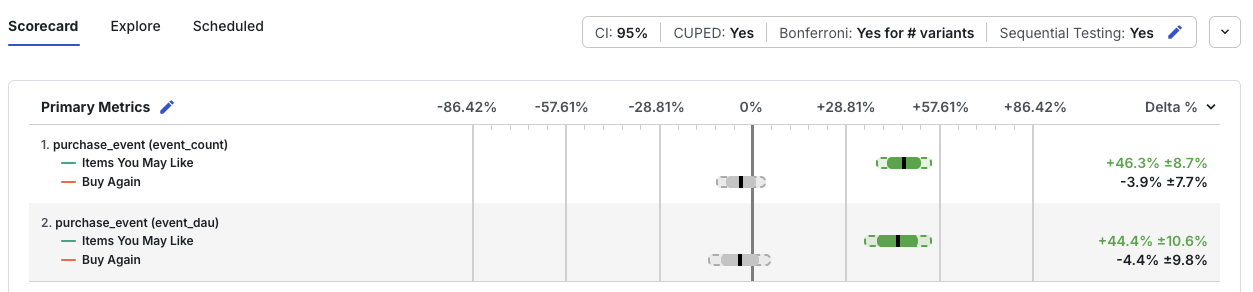
In this example, Statsig expands the confidence intervals for each metric using the "wings" or "tabs". This expansion is a quick visual indicator that sequential testing is on and shows how much the intervals expanded.
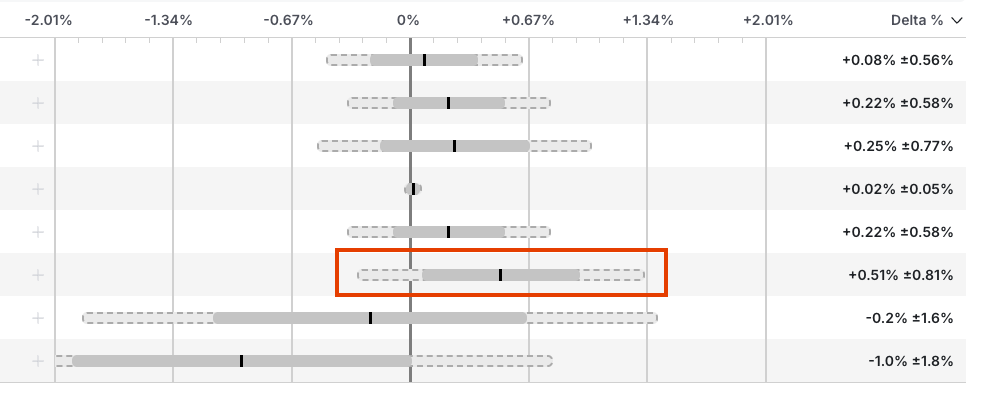
In this example, the sequential testing adjustment determines whether Statsig declares the indicated result stat-sig.
The goal of Sequential Testing is to enable early decision making when observations are sufficiently strong to outweigh random fluctuations, while limiting the risk of false positives. Although Statsig typically discourages peeking, regular monitoring with sequential testing is valuable in some cases:
- Unexpected regressions: When experiments have bugs or unintended consequences that severely impact key metrics, sequential testing helps identify these regressions early and distinguishes significant effects from random fluctuations.
- Opportunity cost: A significant loss may result from delaying the experiment decision, such as launching a new feature ahead of a major event or fixing a bug. In these cases, sequential testing can support an early decision if key metrics show improvement. Use caution: an early stat-sig result for certain metrics doesn't guarantee sufficient power to detect regressions in other metrics. Limit this approach to cases where only a small number of metrics are relevant to the decision.
Quick guides
Enable sequential testing results
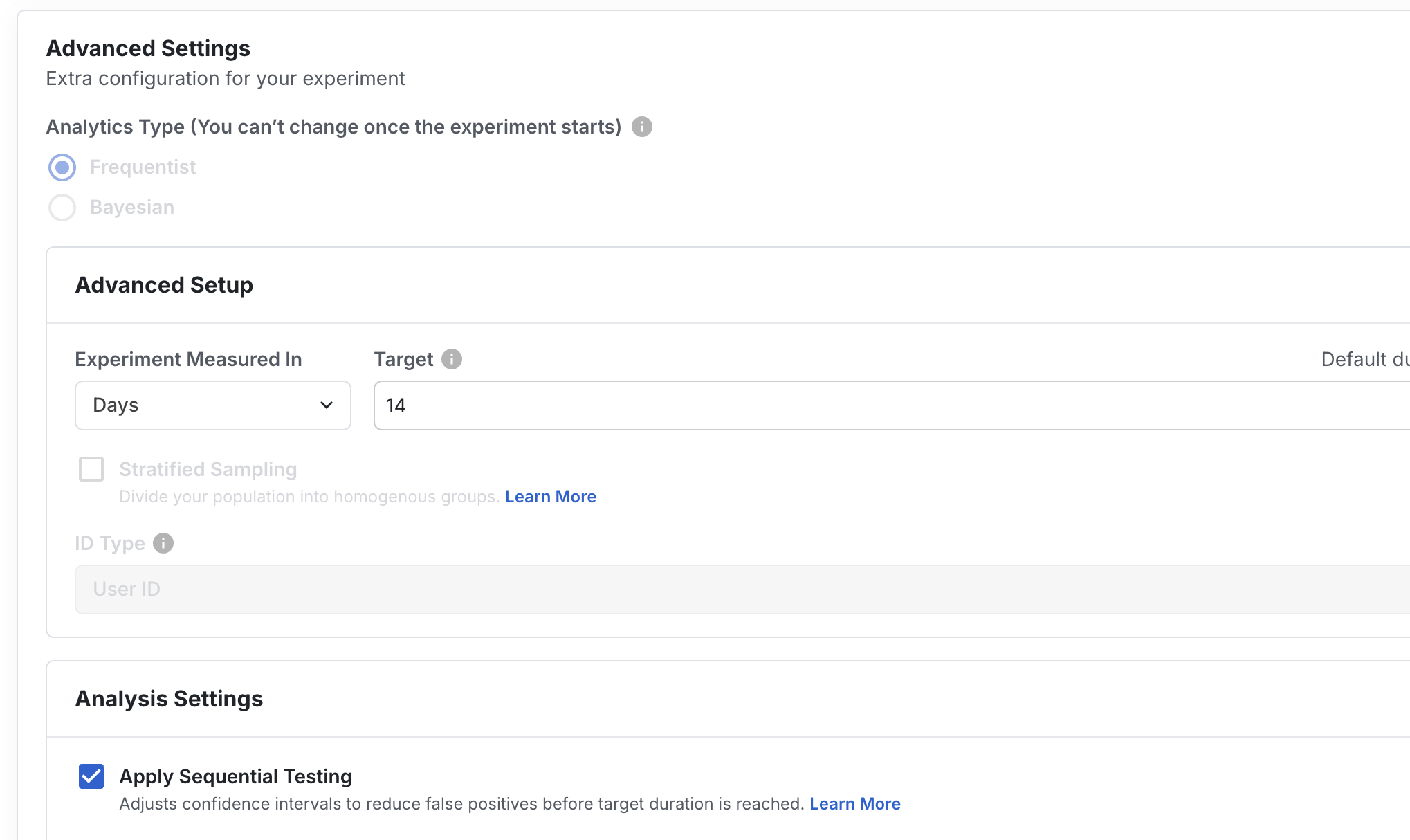
In the Setup tab of your experiment, with Frequentist selected as your Analytics Type, enable Sequential Testing under the Analysis Settings section. You can toggle this setting at any time during the life of the experiment and don't need to enable it before the experiment starts.
Interpreting sequential testing results
Click Edit at the top of the metrics section in Pulse to toggle Sequential Testing on/off.
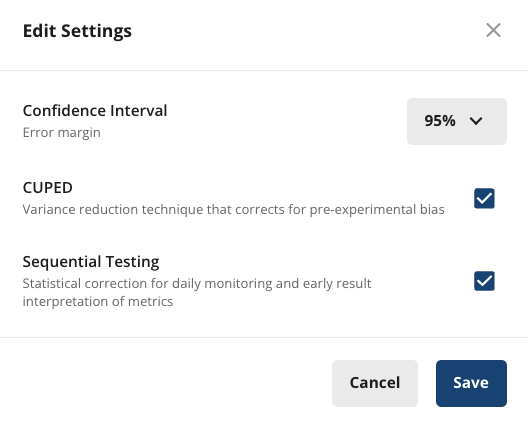
When you enable sequential testing, Statsig applies an adjustment to results calculated before the target completion date of the experiment.

The dashed line represents the expanded confidence interval resulting from the adjustment. The solid bar is the standard confidence interval computed without any adjustments. If the adjusted confidence interval overlaps with zero, the metric delta isn't stat-sig at the moment, and the experiment should continue as planned.
Sequential testing is a reliable way to make an early decision, particularly for early detection of regressions. Early decision-making often results in underpowered lift estimates with a high degree of uncertainty. If making the correct decision is important, use statistically significant sequential testing results. If accurate measurement is important, wait for the full power that your pre-experimental power calculation estimates. Statsig doesn't calculate statistical power on post-hoc experimental results (refer to section "Post-hoc Power Calculations are Noisy and Misleading" in Kohavi, Deng, and Vermeer, A/B Testing Intuition Busters).How Statsig implements Sequential Testing
Two-sided tests
Confidence intervals
Statsig uses mSPRT based on the approach that Zhao et al. propose in this paper. The two-sided Sequential Testing confidence interval with significance level is:where
- is the z-critical value, modified for sequential testing:
- is the standard variance of the delta of means when computing variance. You can obtain it from the sample variance of the test and control group means:
- is the mixing parameter:
- is the z-critical value used in the non-sequential test, for the significance level you want (1.96 for the standard )
p-values
To produce p-values for sequential testing that are consistent with the expanded confidence intervals above, modify the p-value methods.The goal is to evaluate the mSPRT test so that the Type I error remains approximately equal to , and so that the sequential testing p-value is consistent with the expanded confidence interval. (I.e. A CI that includes 0.0% should have p-value ≥ , and one that excludes 0.0% should have p-value < .)
The observed z-statistic (i.e. z-score) remains unchanged. Instead of evaluating on a standard-normal distribution , Statsig evaluates against another normal distribution with mean of zero and standard deviation . For a two-sided test, to limit the probability of an observed exceeding (assuming the null hypothesis to be true) to , you can find the unknown parameter by solving for :
From here, you can compute the two-sided sequential testing p-value as:
where is the observed z-statistic (i.e. z-score) as usual.
One-sided tests
Statsig modifies each step for one-sided sequential testing.
where
- is the one-sided test z-critical value, modified for sequential testing:
is the same as for two-sided tests.
is the mixing parameter:
is the one-sided z-critical value used in the non-sequential test, for the significance level you want (1.645 for the standard )
Statsig solves for with:
- is the (signed) observed z-statistic as usual (i.e. z-score)
Was this helpful?