Pre-Experiment Bias
How Statsig detects and corrects for pre-experiment bias caused by uneven user distributions between treatment and control groups before exposure.
Pre-experiment bias occurs when users in two experiment groups have meaningfully different average behaviors before your experiment applies any intervention. If this difference persists after your experiment starts, experiment analysis may attribute that pre-existing difference to your intervention, making a result appear more or less significant than it is.
CUPED helps address this bias, but can't fully account for it. Some metrics, such as retention, aren't suitable candidates for CUPED, and you can't easily adjust them.Statsig proactively measures the pre-experiment values of all scorecard metrics for all experiment groups, and determines whether the values are significantly different and could cause misinterpretations. If Statsig detects bias, it notifies users and places a warning on relevant Pulse results.
How it works
Statsig provides a "Days Since Exposure" view to help identify novelty effects and pre-experiment effects. For example, the test group in the experiment below had a consistently higher mean than the control group in the week before exposure for this metric.
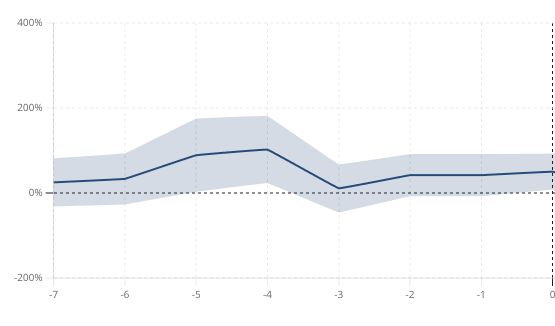
What to do
Pre-experiment bias can occur by chance and isn't always a major issue.
- If the total delta is small, it may not meaningfully influence your interpretation of results.
- If CUPED can account for the bias, the bias shouldn't affect your results.
In many cases, the warning is informational and you can proceed while treating impacted metrics with caution. Proceeding is often appropriate if the metric isn't critical to the experiment, or if you care more about the directional movement than the exact number. Additional time may also reduce the bias when there is no systemic source, as new users dilute the initial imbalance.
If the metric is critical to your analysis and you need the exact numerical value, consider resalting and restarting the experiment.
Was this helpful?