Bonferroni Correction
How Statsig applies the Bonferroni correction to adjust p-values when testing multiple metrics or comparisons in an experiment to control false positives.
What is Bonferroni correction
A Bonferroni Correction is a statistical method that reduces the probability of false positives by adjusting the significance level for multiple comparisons.
Bonferroni controls the family-wise error rate, the chance of any false positive. Use Bonferroni when even one false positive is costly. Use the less strict Benjamini-Hochberg procedure when you're testing many metrics and want to control the false discovery rate instead.If you run a test with α = 0.05, the probability of a false positive is 5%. Running more comparisons at the same significance level increases the chance of at least one false positive, because each comparison is an additional opportunity for a false positive.
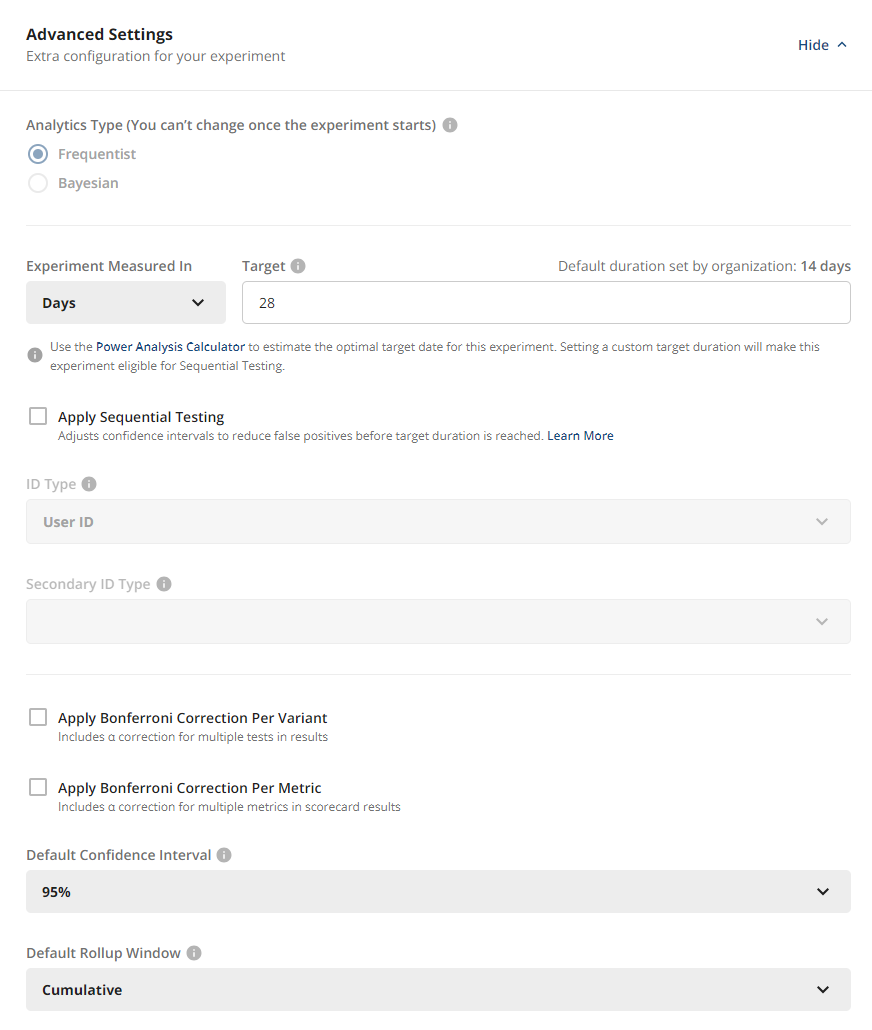
Bonferroni correction is an optional feature on Statsig experiments. Statsig divides the significance level (α) by the number of comparisons it evaluates.
You can apply Bonferroni correction based on one or both of the following:
- The number of test groups (multiple treatment hypotheses). Statsig divides the significance level by the number of variants it compares against control.
- The number of metrics in the scorecard. Here you may select what percentage of your total α Statsig divides evenly among the Primary Metrics, and Statsig splits the remaining α equally among Secondary Metrics. For example:
- Significance level of 0.05
- 2 Primary Metrics and 4 Secondary Metrics
- 60% of α applied to Primary Metrics
- Statsig calculates each Primary Metric with α = 0.6 * 0.05 / 2 = 0.015
- Statsig calculates each Secondary Metric with α = 0.4 * 0.05 / 4 = 0.005
- If you select both corrections, Statsig applies them together. In the example above, to also correct for having 2 test groups, divide each α by 2.
When analyzing dimensions, if you enable correction for metrics, Statsig applies the correction separately for the dimensional breakdown. Statsig uses the number of dimensions as the total metric count for the dimensional analysis, but this approach doesn't impact topline metrics.
How Bonferroni correction affects experiment metrics
In the experiment scorecard section, Statsig derives confidence intervals for applicable metrics from (1 - adjusted α). Hovering over a confidence interval displays the adjusted α alongside other relevant metric details.
In the experiment explore section, Statsig calculates a new adjusted α based on your selections, and the confidence intervals use (1 - adjusted α).
Was this helpful?