Prompts & Graders
Manage AI prompts and graders in Statsig to evaluate, version, and roll out prompts in production without deploying code, similar to dynamic configs.
What is a prompt in Statsig?
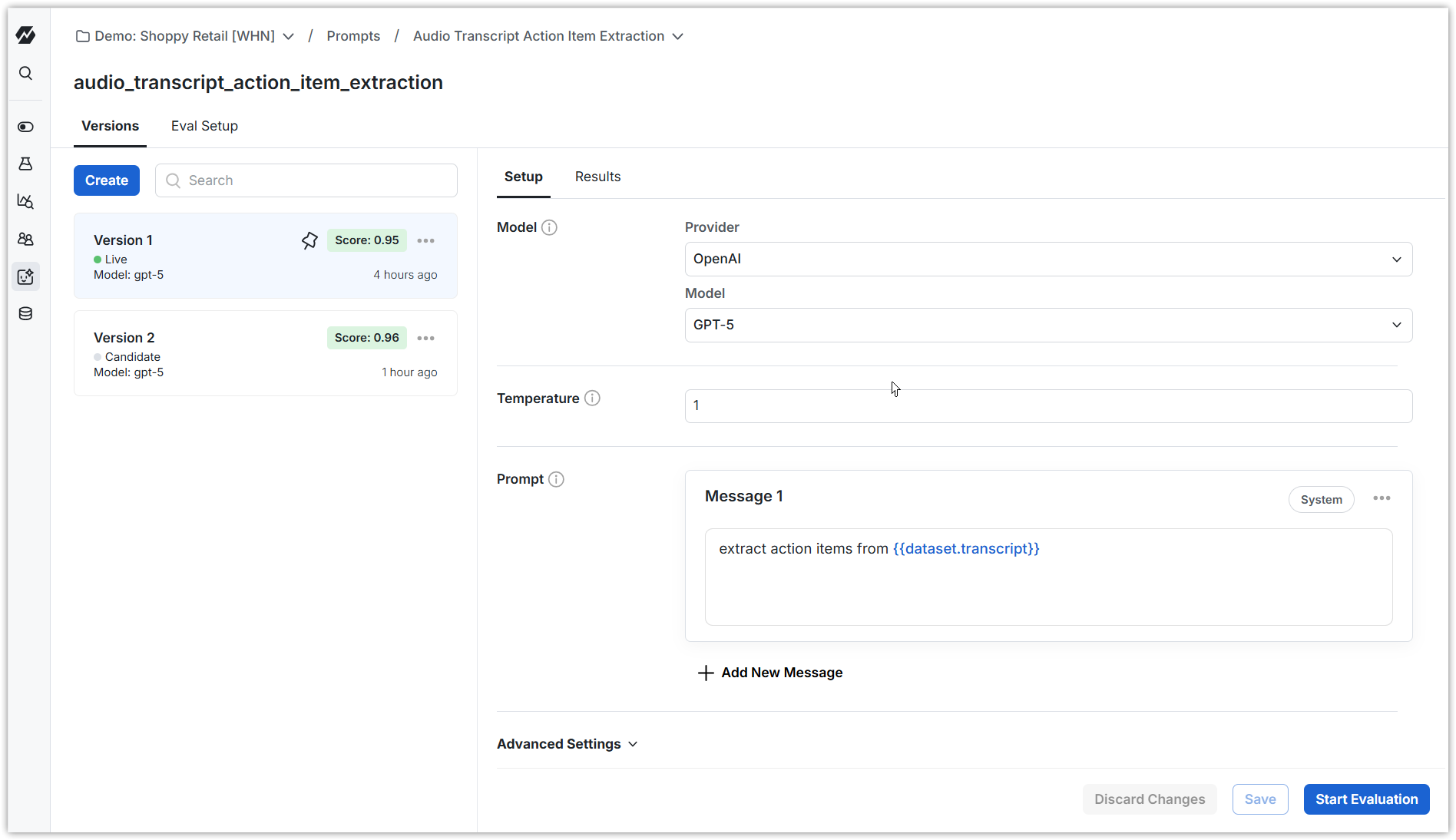
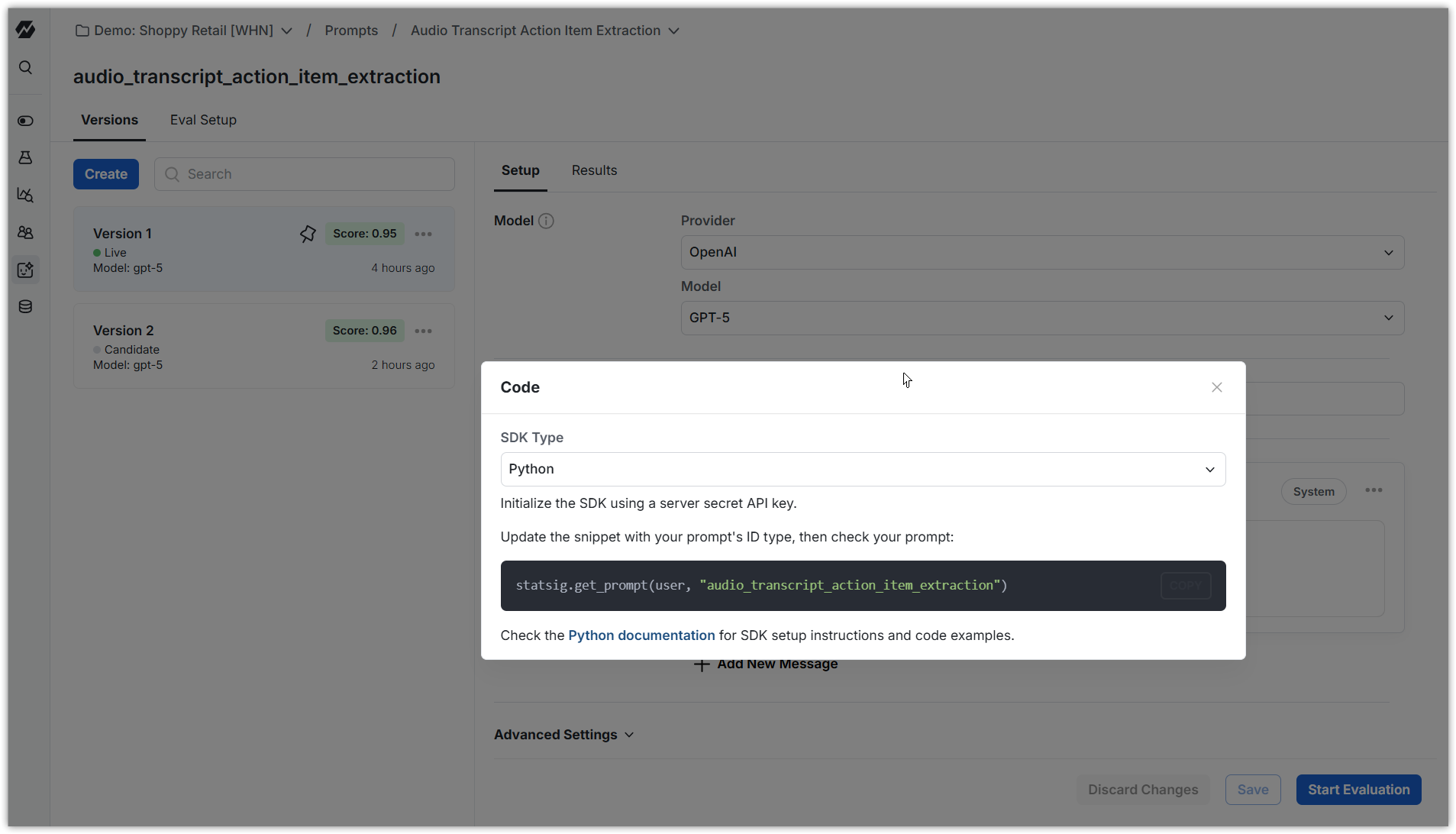
A Prompt represents an LLM prompt or task in Statsig, along with its config. Prompts are similar to Dynamic Configs: you can evaluate and roll out prompts in production without deploying code. Use the Statsig Node or Python Server Core SDKs to retrieve a prompt within your app at runtime.With Prompts, you can:
- Manage prompt configuration outside of your application code. You can update the model, configuration, or prompt at runtime.
- Allow teammates with access to Statsig to collaborate and iterate on prompts, benefiting from Statsig's production change control processes and versioning.
- Add configuration for a new model or model provider and progressively shift production traffic to it while comparing costs, user satisfaction, or any metric of interest.
- Support advanced use cases such as retrieval-augmented generation (RAG) and evaluation in production.
What is a grader?
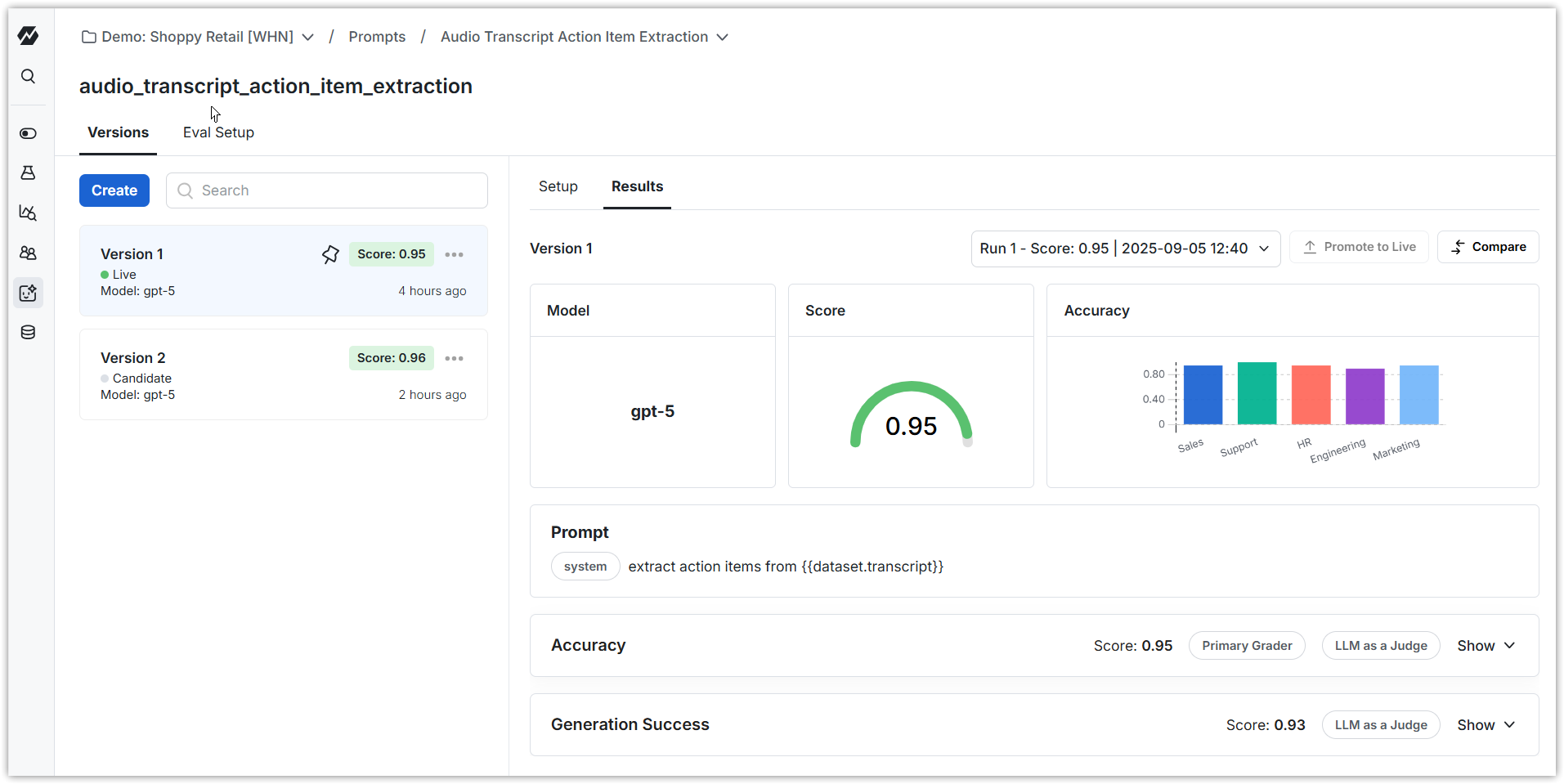
A grader is the evaluation component that scores or judges the output of an AI system against a target standard.
The grader is the core evaluation unit in the workflow:
- Inputs: The grader takes in the AI model’s response and, when available, the ideal or ground-truth answer.
- Process: The grader applies a scoring method. This can be rule-based (exact string match, regex check, cosine similarity) or LLM-as-a-judge (using another model to evaluate correctness, relevance, style, or safety).
- Outputs: The grader produces a score, ideally 0 (Fail) or 1 (Pass). This score feeds into the Statsig experiment or eval framework to determine performance across datasets, experiments, or model versions.
What is a critical grader?
A critical grader is a must-pass evaluation in Statsig AI Evals. If the AI output fails this grader, Statsig marks the entire run as failed. A critical grader enforces non-negotiable requirements, acting as a hard gate before Statsig considers results valid. When it doesn't fail, it acts like a normal grader.
Use case
For example, in a financial support chatbot, a critical grader could check that the model never fabricates account balances. Even if the response is otherwise helpful, a single failure blocks the model's promotion.
Was this helpful?