Sequential Probability Ratio Tests
Learn about SPRT methodology for faster A/B test decision making with no penalties for peeking.
What is SPRT
The Sequential Probability Ratio Test (SPRT) is an advanced methodology for running A/B tests that differs from the traditional Null Hypothesis Significance Test (commonly called Frequentist analysis). SPRT can meaningfully improve time to decision for your experiments, including detecting unwanted metric regressions much faster. SPRT results are also easier to share with stakeholders who aren't familiar with P-values and significance levels. SPRT has no penalties for peeking; there is no need for sequential testing plans, alpha spending, or CI-penalties because SPRT is a sequential test methodology from the start.Use SPRT over frequentist sequential testing when you want unlimited peeking with no alpha-spending or confidence-interval penalties. SPRT also lets you accept either the null or the alternative hypothesis instead of only rejecting the null.
Concepts
SPRT introduces a few key concepts that differ from standard Frequentist tests. At its core, SPRT relies on the Likelihood Ratio (LR) and Upper and Lower decision boundaries, A and B.
The Likelihood Ratio estimates the relative difference in the likelihood of two outcomes:
- Numerator: What you observe is due to an alternative hypothesis (you set) being correct.
- Denominator: What you observe is due to the null hypothesis being correct.
Your joint tolerances for Type I and Type II errors determine the Upper and Lower decision boundaries.
- A: If LR exceeds this upper threshold, accept the Alternative Hypothesis.
- B: If LR is less than this lower threshold, accept the Null Hypothesis.
- When LR falls into the range between these thresholds, you can't make a decision and should continue collecting data.
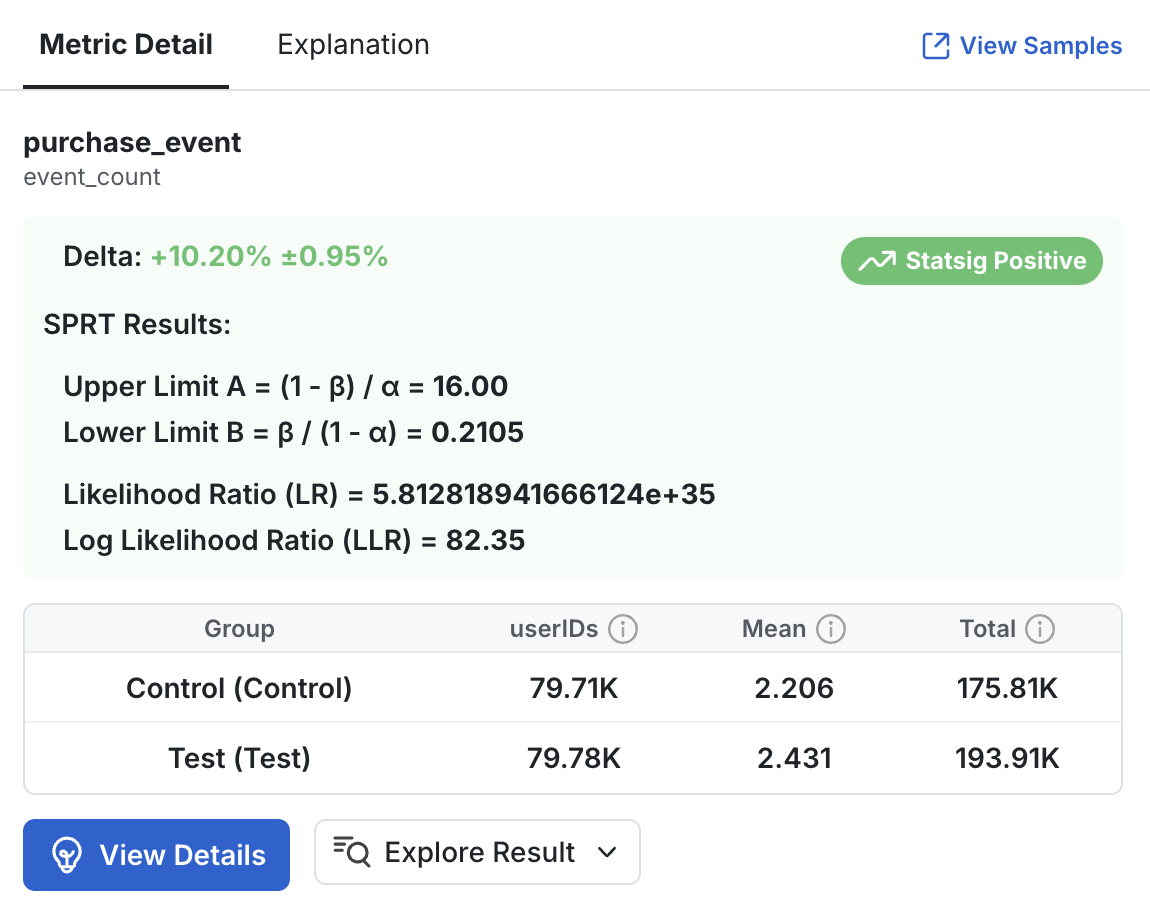
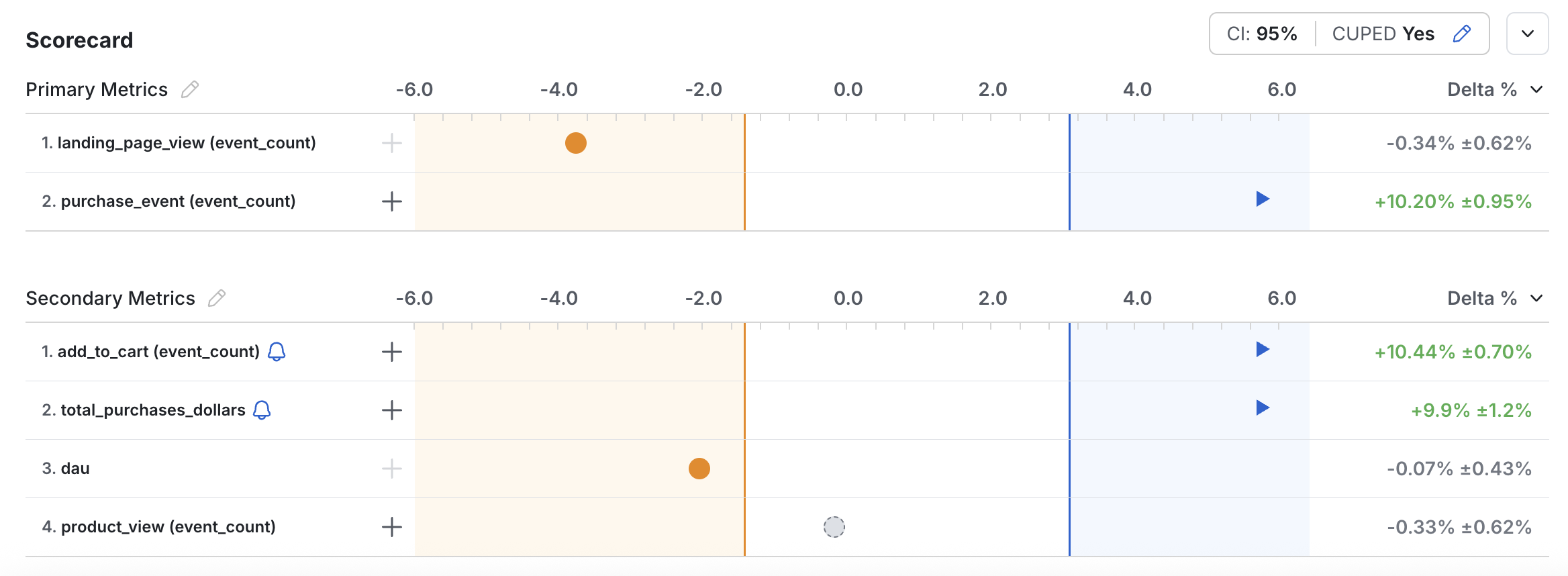
An LR of 5.8, for example, indicates that what you observed is 5.8x more likely under the alternative hypothesis than under the null hypothesis.
The Likelihood Ratio aligns with how most people think about comparing options. Rather than reporting P-values and significance levels, you can report a result such as "With an LR of 3.5, it's 3.5x more likely that the feature worked."
Why SPRT
- Faster decisions: SPRT allows you to reach conclusions more quickly, potentially reducing experiment run time.
- Intuitive results: Instead of p-values, SPRT uses the Likelihood Ratio, a more intuitive measure of evidence for or against your hypotheses.
- Sequential analysis: Statsig continuously evaluates data as it's collected, allowing for early stopping when there's sufficient evidence. There's no penalty for “peeking” in SPRT experiments.
- Clear outcomes: SPRT enables you to confidently accept either the Null or Alternative hypothesis, rather than just “rejecting the null.”
- Data-informed: Statsig’s implementation uses your past data and power analysis to inform the likelihood calculations and decision thresholds.
Comparing SPRT to other analysis methods
| Category | Frequentist | Bayesian | SPRT |
|---|---|---|---|
| Test Statistic | P-value: Probability of observing the results that are as extreme as the sample data if the null hypothesis is true | Posterior Probability: Probability of Test better than Control given the observed data and your prior information | Likelihood Ratio: Comparing the goodness of fit of two competing statistical models |
| Decision Threshold | Alpha (Industry standard 5%) | Posterior Probability and Credible Intervals | Upper & Lower Decision Boundary decided based one the alpha and beta you picked |
| Decision Framework | Reject/Fail to Reject the Null based on if p-value > 5% | Whether chance to beat control exceeds the pre-set decision threshold | Accept the Null Hypothesis, Accept Alternative Hypothesis, Or Continue based on the comparison of calculated likelihood ration with Upper/Lower Decision boundary |
| Allows Peeking | Yes, but with Sequential Testing Penalties | Yes, Unlimited | Yes, Unlimited |
| Requires Pre-Setup | Yes, requires sample size calculation based on historical metric mean and MDE | Optional, but you can define prior distribution per metric if you have previous knowledge which can accelerates the experiment or correct surprising results | Yes, requires historical information about each metric as well as MDE |
| Allows 1- and 2-Sided tests | Yes, per metric | Yes, per metric | Yes, per metric |
How to use SPRT in Statsig
Enabling SPRT: Select SPRT as your analysis method when setting up an A/B test in the Statsig console.
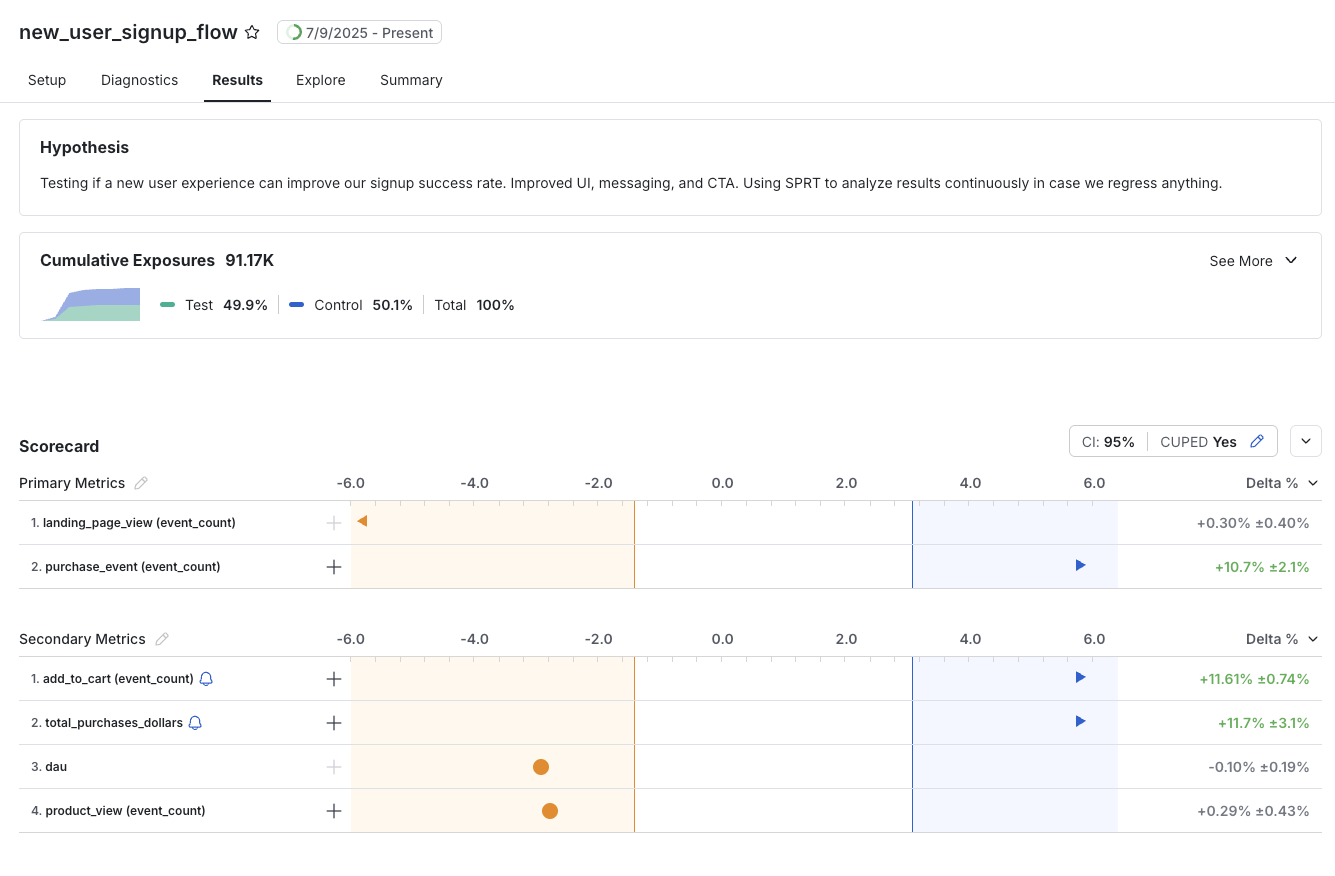
Interpreting Results: The experiment Results tab shows the latest likelihood ratio for each metric and indicates when results reach a decision boundary, letting you accept the null or alternative hypothesis with confidence.
Computing SPRT results
Statsig uses an updated version of Hajnal's two-sample t test (Schnuerch and Erdfelder, as modified by Derek Ho of Atlassian) in its SPRT calculations. The traditional ratio test using t- or F-distributions (Schnuerch and Erdfelder equations 8 & 10) simplifies to a ratio of standard-normal distributions.where:
- is the PDF of a normal distribution of shape evaluated at
- is the observed Z-statistic between the groups
- derives from Cohen's d, which you set before the experiment for the particular metric under consideration
- and are the number of observed units for each group
Since log likelihood ratios are a more convenient scale for reporting, taking the natural log of the LR value above simplifies the equation further:
Power analysis and setting Cohen's d
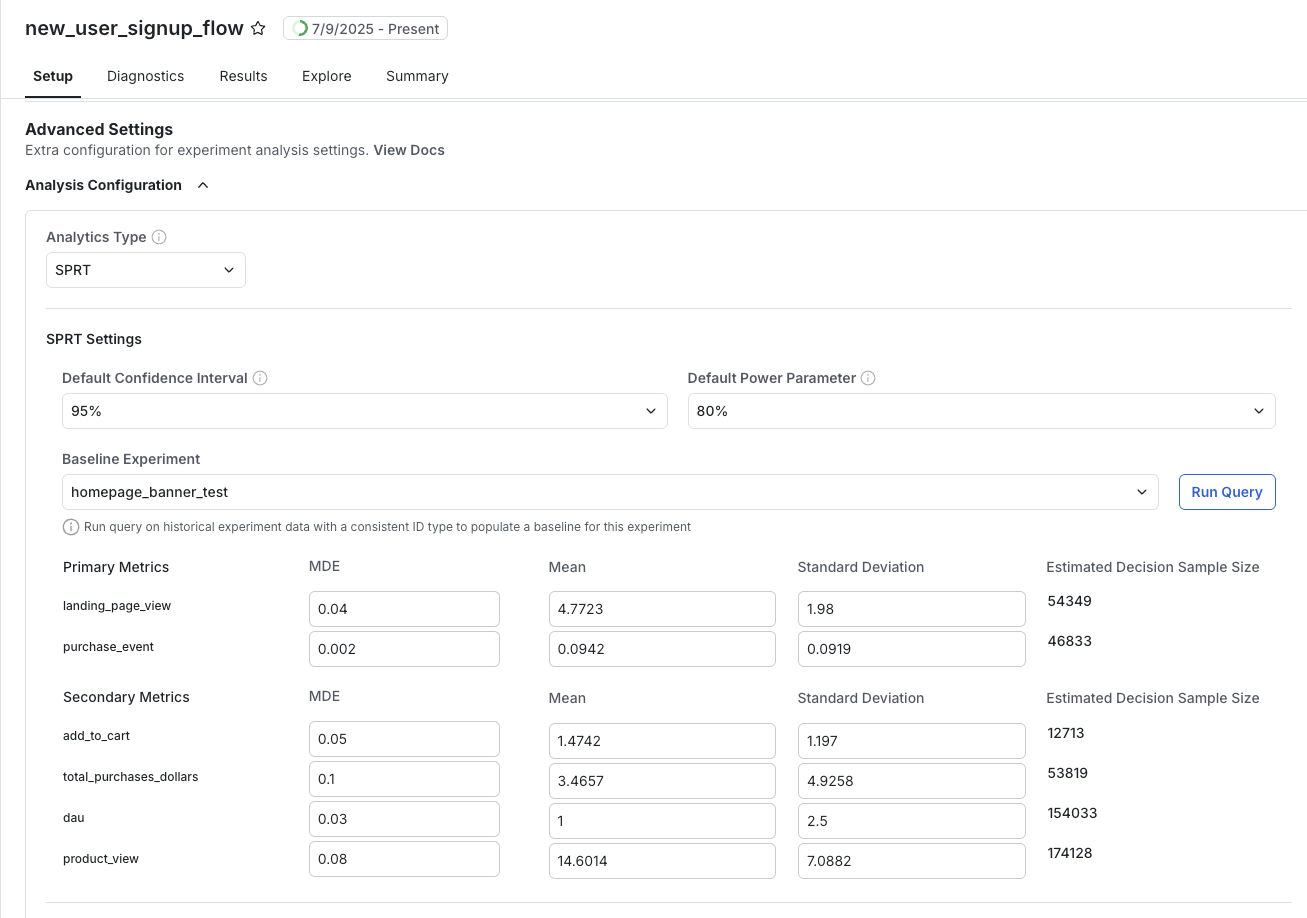
SPRT requires that you set a value of Cohen's d before the start of the experiment for each metric you evaluate. Setting the parameter requires three components:- MDE: A Minimum Detectable Effect to measure, in units of percent
- Mean: A baseline average value for the metric,
- Standard Deviation: A baseline standard deviation for the metric,
With these values, you can compute Cohen's d parameter for each metric:
You can automate this process using Statsig's built-in query tooling. If you have a past experiment that ran on a similar set of units expected in the upcoming experiment, configure that experiment as a Baseline Experiment. A query then automatically pulls the relevant metric parameters. You can also input all three parameters manually.
Estimating the decision sample size
Statsig uses Cohen's d to compute experimental results after the experiment starts, but it can also estimate experiment duration in advance. Because SPRT allows you to look at results as often as you want, this estimate isn't the same as a "required sample size" in traditional frequentist testing. The Decision Sample Size is an estimate of the number of samples sufficient for an SPRT result for a metric to exceed either threshold and accept one of the hypotheses.
Given:
Then, the total number of expected units at decision time is:
Related resources
- Original SPRT Paper (Wald, 1945)
- The Sequential Probability Ratio t Test (Schnuerch & Erdfelder, 2020)
- A two-sample sequential t-test (Hajnal, 1961)
FAQ
Can I use SPRT for all experiments?
SPRT is best suited for experiments where you want faster, sequential decisions and are comfortable with likelihood-based inference. For some experiment types, traditional methods may still be preferable.
How does SPRT affect experiment duration?
SPRT can reduce experiment duration, especially when there is strong evidence for or against an effect. However, if the effect is small or data is noisy, the test may run longer.
What are the limitations?
SPRT requires careful setup of thresholds and assumptions. It isn't a drop-in replacement for all frequentist methods, and may not be suitable for all experiment types.
Was this helpful?